Try/Catch: Origem, Propósito e o Erro de Usá-lo como Fluxo Lógico
O tratamento de exceções surgiu para separar o fluxo normal do programa do tratamento de situações inesperadas, como falhas de hardware ou erros de entrada/saída. Inicialmente, programas usavam códigos de retorno para lidar com erros, mas isso era propenso a falhas e difícil de manter.
O modelo try/catch foi evoluindo desde os anos 60, ganhando formas mais estruturadas em linguagens como PL/I, Ada, C++ e Java, e depois sendo adotado por outras como JavaScript.
O objetivo sempre foi permitir que programas lidassem de forma controlada com erros imprevisíveis, sem travar o sistema. As exceções não foram criadas para controlar o fluxo normal do programa, mas sim para tratar casos realmente excepcionais. Neste artigo, vamos ver por que usar try/catch como controle de fluxo é um erro e qual é o seu propósito real.
Propósito do Try/Catch
A linguagem PL/I (1964) foi pioneira ao introduzir um sistema estruturado de tratamento de condições excepcionais através do constructo ON ... DO para casos como falhas de operações de I/O (entrada/saída) e outros erros de execução.
Esse mecanismo de handlers de erro já demonstrava a vantagem de estruturar o código para lidar separadamente com situações de erro. SIMULA 67 – precursora da programação orientada a objetos, introduzindo conceitos fundamentais como classes e herança – focou principalmente em contribuições para paradigmas de programação, não em mecanismos de tratamento de exceções. Em essência, o modelo PL/I possuía:
- Bloco Protegido – equivalente funcional ao bloco
try, delimitando o código onde erros poderiam ocorrer. - Rotina de Tratamento (Handler) – definida via construções
ON ... DO, análoga aocatchatual, executada caso uma condição excepcional fosse detectada.
Um exemplo simplificado em pseudo-sintaxe inspirada no PL/I ilustrava essa estrutura:
BEGIN;
ON ERROR DO BEGIN;
/* Código de recuperação (handler) */
END;
/* Bloco protegido (código propenso a erro) */
...
END;Desde cedo, a ideia de separar o código principal do tratamento de erros foi vista como um grande avanço, pois deixava os programas mais organizados e fáceis de entender. O PL/I trouxe esse conceito pioneiramente em 1964, mas quem realmente mudou o jogo foi o Lisp.
Versões do Lisp nos anos 1970 introduziram as funções catch e throw como um mecanismo de controle de fluxo não-local — uma forma de “saltar” diretamente para um ponto específico da pilha de chamadas, ignorando o código intermediário. É importante distinguir que catch/throw no Lisp não eram propriamente um sistema de tratamento de exceções, mas sim uma ferramenta de controle de fluxo.
Basicamente, marcava-se um ponto de captura com uma tag simbólica usando catch e, quando necessário, utilizava-se throw com a mesma tag para desviar imediatamente a execução para lá. Esse mecanismo era útil para sair de loops aninhados ou retornar de funções profundamente encadeadas, mas não oferecia tipagem de erros, handlers especializados ou capacidade de reinício como um sistema de exceções moderno.
O verdadeiro avanço do Lisp no tratamento de exceções veio posteriormente com o Common Lisp Condition System, que introduziu conceitos sofisticados como handlers tipados, restarts (pontos de recuperação) e a separação entre sinalização (signal) e tratamento de condições. Este sistema permite não apenas capturar erros, mas também corrigi-los e continuar a execução — um paradigma que vai além do simples try/catch e influenciou sistemas modernos de tratamento de erros.
A distinção é crucial: enquanto catch/throw eram ferramentas de controle de fluxo (similares a um goto estruturado), o Condition System modelava verdadeiramente o tratamento de situações excepcionais com tipagem, recuperação e estratégias de reinício — conceitos que inspiraram os mecanismos modernos de exceções em linguagens como C++ e Java.
Consolidando essa evolução histórica, linguagens como C++ formalizaram e refinaram esses conceitos pioneiros por meio das estruturas try e catch, introduzindo um sistema de exceções baseado em tipos. Em C++, por exemplo, podemos proteger um bloco de código e tratar erros assim:
try {
// Código que pode lançar exceções
throw std::runtime_error("Erro!");
} catch (const std::exception& e) {
// Tratamento da exceção
std::cerr << "Exceção capturada: " << e.what();
}O objetivo principal desse mecanismo é ajudar os programadores a lidar com problemas que ocorram durante a execução de forma organizada, separando claramente a lógica normal do tratamento de erros. Ele leva adiante – e aprimora – os princípios introduzidos por linguagens como PL/I e Lisp, porém com uma implementação mais robusta e integrada à tipagem da linguagem.
Nesse ponto, vale destacar um princípio essencial do livro The Pragmatic Programmer, que recomenda: “Crash early” — ou seja, falhe cedo e com clareza quando algo realmente inesperado ocorre. Segundo os autores, “dead programs tell no lies” — um programa que trava rapidamente pode ser mais confiável que um inválido operando silenciosamente com dados corrompidos. Isso reforça o propósito original das exceções: detectar falhas graves imediatamente, evitando consequências imprevisíveis.
Antes de explorarmos os detalhes técnicos e as melhores práticas do uso de try/catch, é importante entender o propósito fundamental desse mecanismo no contexto da programação moderna. O tratamento estruturado de exceções surgiu para resolver problemas clássicos de legibilidade, robustez e manutenção do código, especialmente em situações onde o fluxo normal de execução pode ser interrompido por eventos inesperados.
A seguir, vamos analisar como o try/catch evoluiu historicamente, quais problemas ele resolve em relação a abordagens mais antigas (como códigos de erro) e por que sua adoção tornou-se um marco na organização e clareza dos programas:
- Problemas com Códigos de Erro: Com códigos de retorno, o chamador pode simplesmente esquecer de verificar se ocorreu um erro. Quando isso acontece, o programa continua executando como se tudo estivesse normal, mesmo que tenha ocorrido um problema sério.
O exemplo abaixo ilustra como isso pode levar a situações indesejadas – a função read_int() retorna um código indicando erro ou sucesso, mas se quem a chamou não conferir esse código, um valor inválido poderá ser usado em cálculo a seguir:
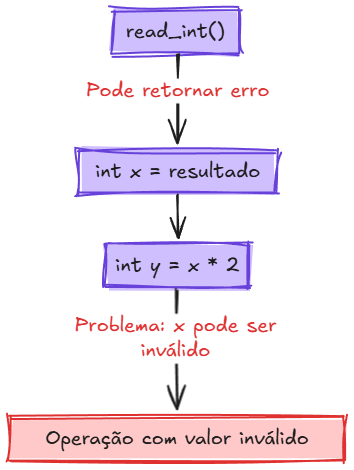
No diagrama, vê-se um fluxo onde read_int() pode indicar uma falha, mas esse retorno não é verificado ao atribuir o resultado à variável x. Em consequência, o programa segue seu curso normal, calculando y = x * 2 mesmo que x possa conter um valor inválido. Isso resulta em uma operação com dado incorreto no final do fluxo, demonstrando como a falta de verificação de erros pode propagar problemas silenciosamente pelo programa.
- Separação de Preocupações: Com exceções, a detecção de um erro (na função chamada) fica separada do tratamento do erro (na função chamadora). Isso permite um código mais limpo, em que a lógica principal não fica poluída por verificações de erro a cada passo. O tratamento pode ser centralizado em um único lugar, geralmente no nível mais alto da aplicação, enquanto o fluxo normal de execução permanece claro.
O diagrama abaixo ilustra essa separação: o caminho principal (em azul) representa a execução bem-sucedida – inicia, processa dados, salva resultados, envia notificação e finaliza com sucesso. Porém, se em qualquer dessas etapas ocorrer uma exceção, o fluxo é desviado para o bloco de tratamento de erros (em vermelho), onde o erro é registrado e o programa termina de forma controlada.
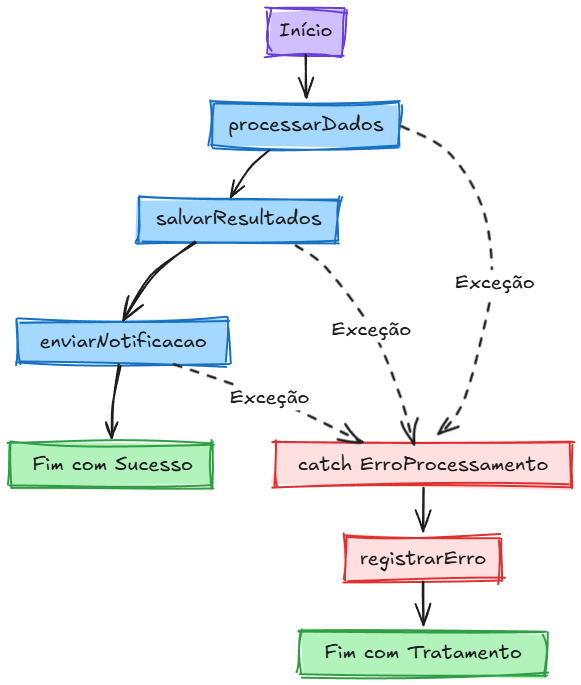
Esse diagrama destaca como o código principal pode se concentrar na lógica de negócio, enquanto o tratamento de erro fica isolado no bloco catch. Essa é a essência do try/catch: permitir que o fluxo “normal” do programa permaneça legível e que todo o código referente a erros esteja agrupado e bem definido em outro lugar. O resultado é um código mais organizado e de fácil manutenção.
- Erros Não Podem Ser Ignorados:
Se uma exceção não for capturada por nenhum handler correspondente, o C++ chama
std::terminate(), que encerra o programa de forma abrupta. Diferentemente de um código de erro que pode ser ignorado sem querer, uma exceção não tratada provoca a finalização do programa, garantindo que erros críticos não passem despercebidos.
O diagrama a seguir mostra dois fluxos possíveis de um programa simples: no caminho normal, a função é executada e imprime uma mensagem (“Esta linha…”) antes de retornar ao main e encerrar normalmente; já no caminho de erro, a função lança uma exceção (std::runtime_error), que não é capturada em nenhuma parte do programa, resultando na chamada imediata de std::terminate() e encerramento abrupto da aplicação. Note que no diagrama, o caminho vermelho representa o comportamento real do C++: unwinding incompleto seguido de terminação forçada.
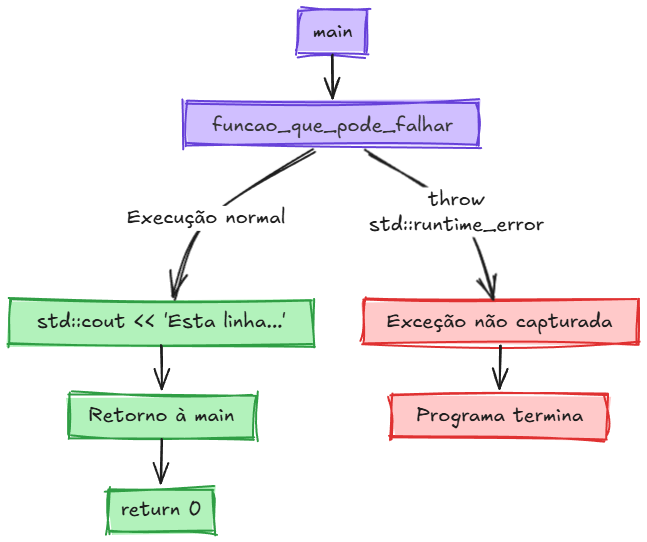
Podemos observar, em rosa, o ponto onde “dá ruim” (onde a exceção é lançada) e, em vermelho, o caminho do erro levando à chamada de std::terminate(). Esse comportamento é intencional: como o próprio Stroustrup explica, “se uma função encontrar um erro que não consiga resolver, ela lança uma exceção; alguma função acima na hierarquia de chamadas pode capturá-la, mas, se ninguém o fizer, o programa termina”.
Detalhes do Comportamento no Diagrama: O caminho vermelho “Exceção não capturada → std::terminate() chamado” reflete o comportamento real do C++. Diferentemente de linguagens que fazem unwinding completo antes de terminar, o C++ chama std::terminate() imediatamente quando nenhum handler é encontrado, interrompendo o processo de unwinding. Isso significa que objetos em frames superiores (como variáveis locais em main) podem não ter seus destrutores executados.
Importante sobre Stack Unwinding: Quando uma exceção não é capturada, o C++ não executa o stack unwinding completo. Em vez disso, std::terminate() é chamado imediatamente, o que significa que destrutores só são chamados para objetos nos frames de pilha que foram efetivamente desempilhados até o ponto onde a exceção foi lançada. Objetos em frames superiores (incluindo objetos locais em main) podem não ter seus destrutores executados.
Embora terminar a aplicação possa parecer drástico, isso na verdade evita consequências piores, como continuar a execução com dados corrompidos. Diferente dos códigos de erro (em que o programador precisa lembrar de verificar cada retorno), as exceções forçam uma decisão: ou você trata o problema em algum lugar, ou o programa será finalizado. Assim, falhas graves não “passam batido”.
A separação clara entre lógica principal e lógica de erro permite a liberação automática de recursos quando há handlers apropriados, graças ao stack unwinding controlado do mecanismo de exceções em C++. Porém, é crucial entender que sem tratamento adequado, essa garantia de limpeza não se aplica.
Principais Usos do try/catch — Exemplos Práticos em Diferentes Contextos
O bloco try/catch é fundamental para lidar com eventos realmente excepcionais — aqueles que interrompem o fluxo normal e não podem ser resolvidos apenas com valores de retorno ou verificações simples. Exemplos clássicos: falta de memória, falhas de I/O, corrupção de dados, ou erros lógicos imprevistos.
A seguir, os principais cenários onde o uso do try/catch é apropriado, já com exemplos comentados em cada contexto:
Falhas de I/O (Arquivos, Rede, Dispositivos)
Situações em que o programa depende de recursos externos — um arquivo, uma conexão de rede, um socket — e o resultado pode variar a qualquer momento, independentemente da lógica do seu código.
try {
std::ifstream arq("dados.txt");
// Por padrão, streams C++ NÃO lançam exceções.
// Para habilitá-las, configure os bits de exceção:
arq.exceptions(std::ios::failbit | std::ios::badbit);
std::string linha;
while (std::getline(arq, linha)) // agora pode lançar exceção
processar(linha);
} catch (const std::ios_base::failure& e) {
// Tipo específico para erros de I/O quando exceções estão habilitadas
logErro("Falha de I/O: " + std::string{e.what()});
logErro("Código de erro: " + std::to_string(e.code().value()));
} catch (const std::exception& e) {
// Captura outros tipos de erro (ex: problemas em processar())
logErro("Erro geral: " + std::string{e.what()});
}- Fluxo normal: abrir, ler, processar.
- Fluxo de erro: qualquer falha salta direto para o
catch.
Importante sobre Streams C++: Por padrão, as streams (
std::ifstream,std::ofstream, etc.) não lançam exceções quando encontram erros — elas apenas definem bits de estado interno (failbit,badbit,eofbit) que devem ser verificados manualmente. Para que uma stream lance exceções automaticamente, é necessário configurar explicitamente quais condições devem disparar exceções usando o métodoexceptions().
No exemplo acima, arq.exceptions(std::ios::failbit | std::ios::badbit) instrui a stream a lançar uma exceção do tipo std::ios_base::failure sempre que ocorrer uma falha de operação (failbit) ou um erro irrecuperável (badbit). Sem essa configuração, operações como std::getline() ou read() falhariam silenciosamente, exigindo verificações manuais de estado.
Alternativa com Códigos de Status (quando exceções não estão habilitadas):
// Tratamento tradicional sem exceções - verificação manual
std::ifstream arq("dados.txt");
if (!arq.is_open()) {
logErro("Erro: não foi possível abrir dados.txt");
return;
}
std::string linha;
while (std::getline(arq, linha)) {
if (arq.bad()) {
logErro("Erro irrecuperável durante leitura");
break;
}
if (arq.fail() && !arq.eof()) {
logErro("Falha na operação de leitura");
break;
}
processar(linha);
}Comparação: Com exceções habilitadas, o try/catch separa claramente o fluxo principal do tratamento de erros usando std::ios_base::failure específico. Sem exceções, você deve verificar manualmente os estados da stream (bad(), fail(), eof()) após cada operação. A abordagem com exceções mantém o código principal mais limpo, enquanto códigos de status oferecem controle mais granular sobre cada tipo de falha.
Conforme discutido por Scott Meyers no seu livro Effective C++, página 61-65, item 13, o uso de RAII e arquiteturas seguras de exceção (exception-safe) garante que recursos sejam sempre liberados corretamente mesmo em falha, movendo o código para o nível de basic ou strong exception safety. Ver também Item 29, p.115.
Papel do RAII: limpeza automática
Em C++ não há finally, porque o RAII resolve a liberação de recursos durante o “desenrolar” da pilha:
#include <fstream>
#include <memory>
void processarArquivo(const std::string& caminho) {
std::ifstream f(caminho); // fecha sozinho no destrutor
if (!f) {
throw std::ios_base::failure("Falha ao abrir: " + caminho);
}
// Configurar stream para lançar exceções em caso de erro
f.exceptions(std::ios::failbit | std::ios::badbit);
auto buf = std::make_unique<char[]>(1024); // libera sozinho
f.read(buf.get(), 1024); // agora pode lançar std::ios_base::failure
// ...processa dados...
} // Se qualquer exceção "subir", f e buf são destruídos aquiQuando uma exceção é lançada, a execução normal do programa é imediatamente interrompida. Nesse momento, todos os objetos locais têm seus destrutores chamados automaticamente, o que garante a liberação dos recursos alocados, como arquivos abertos ou blocos de memória. O controle do fluxo, então, é transferido para o bloco catch mais próximo que seja capaz de tratar aquela exceção.
RAII e Níveis de Segurança de Exceção: O RAII garante automaticamente o nível basic exception safety — o programa permanece em um estado válido após uma exceção, sem vazamentos de recursos. Este é um dos três níveis formais de segurança de exceção em C++:
- No-throw guarantee (forte): A operação não pode falhar — garantido por funções marcadas com
noexcept - Strong exception safety (forte): Em caso de falha, o estado do programa permanece inalterado (como se a operação nunca tivesse sido tentada)
- Basic exception safety (básico): O programa permanece em estado válido, recursos são liberados, mas o estado pode ter mudado
RAII por si só oferece basic safety, mas pode ser combinado com técnicas como copy-and-swap idiom para alcançar strong safety, ou com noexcept move constructors para garantir operações que não falham. Essas garantias formais tornam o código C++ mais previsível e robusto.
Esse mecanismo faz com que, mesmo em situações em que “tudo dá errado”, o programa consiga fechar arquivos, devolver memória e encerrar de maneira previsível. Caso seja apropriado, o programa pode até continuar sua execução após o tratamento, dependendo da gravidade do erro e da lógica implementada.
Por outro lado, é importante não usar try/catch para controlar o fluxo nominal do programa. Exceções não devem ser empregadas para lidar com situações esperadas, como o fim de um arquivo durante uma leitura sequencial. Da mesma forma, se um resultado pode ser tratado por meio de valores de retorno, essa abordagem deve ser preferida. Reservar exceções para falhas realmente irrecuperáveis mantém o código mais claro e eficiente.
Em resumo, o
try/catchserve para isolar o código de negócio do tratamento de falhas, garantir a liberação automática de recursos (graças ao RAII) e evitar que erros críticos passem despercebidos. Essa separação contribui para a clareza, robustez e manutenibilidade do software.
Tratamento de Exceções em Diferentes Contextos
Agora que vimos por que e quando usar try/catch, vamos explorar o mecanismo em ação em cenários do dia a dia. Os exemplos abaixo seguem o mesmo princípio apresentado na seção anterior:
separe a lógica “feliz” do que acontece quando algo dá errado.
Gerenciamento de recursos
void processar() {
auto dados = std::make_unique<Buffer>(1024); // libera sozinho
try {
dados->carregar();
dados->processar();
dados->salvar();
} catch (...) {
logErro("Falha no processamento, propagando...");
throw; // sobe para quem souber tratar
} // `dados` é liberado aqui
}- O
unique_ptrgarante liberação, dispensandofinally. - O bloco
catchadiciona contexto e re‑lança.
O exemplo acima ilustra como o uso combinado de try/catch e RAII (através do unique_ptr) simplifica o gerenciamento de recursos em C++. Ao encapsular a lógica principal dentro de um bloco try, garantimos que qualquer exceção lançada durante o carregamento, processamento ou salvamento dos dados seja capturada no catch, onde podemos registrar o erro e, se necessário, propagar a exceção para níveis superiores.
O uso do unique_ptr assegura que a memória alocada para o buffer será automaticamente liberada ao final do escopo, mesmo que uma exceção ocorra — eliminando a necessidade de blocos finally ou liberações manuais.
Assim, o código permanece limpo, seguro e robusto, pois separa claramente o fluxo normal do tratamento de falhas, um dos principais propósitos do mecanismo de exceções discutido neste artigo.
Validação de dados
class Usuario {
public:
void setIdade(int idade) {
if (idade < 0 || idade > 120)
throw std::invalid_argument("Idade fora do intervalo permitido");
idade_ = idade;
}
private:
int idade_{};
};
try {
Usuario u;
u.setIdade(valorLido);
} catch (const std::invalid_argument& e) {
logErro("Entrada inválida: " + std::string{e.what()});
}- A regra de negócio fica dentro da classe.
- Quem usa a API só precisa lidar com a exceção, sem checar retornos.
O exemplo acima demonstra como encapsular regras de validação diretamente na classe, lançando exceções quando os dados não atendem aos critérios esperados (por exemplo, uma idade fora do intervalo permitido). Isso centraliza a lógica de negócio e simplifica o uso da API, pois quem consome a classe só precisa tratar possíveis exceções, sem se preocupar em checar retornos de erro manualmente.
Esse padrão torna o código mais limpo, seguro e fácil de manter, além de separar claramente o fluxo normal do tratamento de falhas. Essa abordagem de propagação de exceções é especialmente útil em cenários mais complexos, como operações transacionais, que veremos a seguir.
Transações atômicas
void transferir(Conta& a, Conta& b, double v) {
if (v <= 0) throw std::invalid_argument("valor <= 0");
std::scoped_lock lk(a.mtx(), b.mtx()); // C++17: adquire ambos sem deadlock
try {
a.debitar(v);
b.creditar(v);
} catch (...) { // qualquer erro ⇒ rollback
a.creditar(v);
throw;
}
}- All‑or‑nothing: ou ambas as contas mudam, ou nada persiste.
scoped_lockadquire ambos os mutexes simultaneamente e os libera automaticamente, mesmo em caso de exceção.
✅ Prevenção de deadlock: O código utiliza
std::scoped_lock(C++17+) que adquire ambos os mutexes simultaneamente usando um algoritmo livre de deadlock. Isso elimina a necessidade de ordenação manual dos locks e previne deadlocks que poderiam ocorrer comlock_guardseparados quando diferentes threads adquirem os mesmos mutexes em ordens distintas.
O exemplo acima ilustra como implementar uma operação transacional utilizando exceções para garantir a atomicidade: se qualquer etapa da transferência falhar (por exemplo, por saldo insuficiente ou erro inesperado), o código faz o rollback debitando e depois creditando novamente o valor na conta de origem, antes de propagar a exceção.
O uso de scoped_lock assegura que os mutexes das contas sejam adquiridos de forma livre de deadlock e liberados automaticamente, mesmo em caso de erro, evitando tanto deadlocks quanto vazamentos de recursos.
Esse padrão é fundamental em sistemas financeiros e outros domínios críticos, pois assegura que as alterações de estado sejam consistentes e não deixem o sistema em situação intermediária caso ocorra uma falha.
A seguir, veremos como enriquecer o contexto das exceções ao longo das camadas da aplicação, facilitando o diagnóstico e a rastreabilidade dos erros.
Enriquecendo contexto em camadas
void baixa() { /* ... */ throw std::runtime_error("DB offline"); }
void media() { try { baixa(); }
catch (const std::exception& e) {
throw std::runtime_error("Camada média: " + std::string{e.what()});
}}
void alta() { try { media(); }
catch (const std::exception& e) {
throw std::runtime_error("Camada alta: " + std::string{e.what()});
}}O objetivo desse padrão é fornecer uma trilha clara e detalhada do caminho percorrido pelo erro, desde sua origem até o ponto mais alto da pilha de chamadas. Ao enriquecer a mensagem de exceção em cada camada, o desenvolvedor consegue identificar rapidamente onde o problema começou e por quais etapas ele passou, facilitando o diagnóstico e a correção. Esse encadeamento de mensagens resulta em um relatório final como:
"Camada alta: Camada média: DB offline"Exceções devem ser usadas exclusivamente para situações realmente excepcionais, ou seja, aquelas que impedem o fluxo normal do programa de continuar. Não utilize exceções para controlar o fluxo rotineiro da aplicação, pois isso pode tornar o código confuso, difícil de manter e impactar negativamente a performance.
Algumas boas práticas são fundamentais para um uso correto do
try/catch: sempre capture tipos específicos de exceção primeiro, evitando tratar tudo como erro genérico; nunca ignore exceções silenciosamente — registre o erro ou converta-o em um erro de domínio; em C++, garanta o uso de RAII (Resource Acquisition Is Initialization) para liberar recursos automaticamente, dispensando a necessidade de blocosfinallye prevenindo vazamentos (em outras linguagens, utilize os mecanismos equivalentes, comowithem Python ouusingem C#).
Documente claramente quais exceções sua função pode lançar, facilitando o uso e os testes; e lembre-se de que lançar exceções tem custo, então não utilize esse mecanismo para situações comuns do fluxo de controle.
Má prática de design — quando o try/catch vira gambiarra
No tópico anterior, vimos quando é apropriado lançar exceções; agora, é importante abordar o outro lado: o que acontece quando utilizamos try/catch para tratar situações que não são realmente excepcionais. Usar exceções como substituto de verificações normais, como um simples if, é considerado um anti-padrão e pode trazer consequências negativas para a clareza, desempenho e manutenção do código. Observe o exemplo abaixo:
// ❌ Exceção controlando fluxo normal
function getItemPrice(item: { name: string; price?: number }): number {
try {
if (item.price === undefined) // caso esperado
throw new Error("Preço indefinido"); // força exceção
return item.price;
} catch {
return 0; // valor padrão
}
}Usar exceções para tratar situações rotineiras, como uma simples validação de campo, é prejudicial por vários motivos. Primeiro, isso surpreende quem lê o código, pois dá a impressão de que ocorreu uma falha grave, quando na verdade é apenas um caso esperado e trivial — quebrando o Princípio do Menor Espanto (POLA).
Além disso, lançar e capturar exceções é uma operação significativamente mais custosa do que um simples if. O modelo C++ usa “zero-cost exceptions” — que significa zero custo apenas no caminho normal (quando nenhuma exceção é lançada) — mas o custo de realmente lançar uma exceção é extremamente alto. Como explica Raymond Chen, da Microsoft, o termo pode ser enganoso: “Metadata-based exception handling should really be called super-expensive exceptions”.
O processo envolve: busca por metadados no PC (program counter), decodificação de dados DWARF compactados, chamadas ao personality routine, e o custoso stack unwinding. Herb Sutter demonstra que exceções violam o zero-overhead principle do C++, sendo uma das únicas duas funcionalidades da linguagem (junto com RTTI) que têm opções para serem desabilitadas pelos compiladores.
Adicionalmente, mesmo quando não lançadas, exceções podem limitar certas otimizações do compilador: antes de operações que podem gerar exceção, o compilador pode precisar descarregar registradores para memória e evitar reordenações que quebrariam a semântica de unwinding. As C++ Core Guidelines enfatizam que “exceptions are for error handling only” e que usar exceções para controle de fluxo normal “makes code hard to follow and maintain.”
Essa ideia está diretamente alinhada ao conselho do livro The Pragmatic Programmer: trate apenas o que realmente é excepcional como exceção — caso contrário, você adiciona complexidade desnecessária e viola princípios como Principle of Least Astonishment.
Além disso, conforme Matt Klein argumenta em seu artigo “Crash early and crash often for more reliable software” (7 abr 2019), verificações de erro excessivas prejudicam a confiabilidade do software. Ele afirma literalmente: “The only error checking a program needs are for errors that can actually happen during normal control flow” (A única verificação de erro que um programa precisa é para erros que podem realmente acontecer durante o fluxo de controle normal).
Klein explica que checks desnecessários aumentam a complexidade e geram dívida de manutenção ao proliferarem ramos de código raramente exercitados, que por sua vez se tornam fontes de bugs ocultos e comportamentos imprevisíveis.
Outro problema é que esse uso inadequado de exceções polui o stack-trace, tornando mais difícil depurar e analisar o comportamento do sistema. O excesso de exceções desnecessárias pode mascarar erros reais, dificultar o profiling e tornar o código mais difícil de manter.
Por isso, para validações simples e previsíveis, prefira sempre estruturas de controle explícitas, reservando as exceções apenas para situações realmente inesperadas ou graves. Vamos ver um exemplo idiomático em TypeScript:
// ✅ Política de negócio explícita (se 0 é valor válido)
function getItemPrice(item: { name: string; price?: number }): number {
return item.price ?? 0; // política: preço indefinido = gratuito
}
// ✅ Tratamento de erro de domínio (se preço é obrigatório)
function getItemPriceStrict(item: { name: string; price?: number }): number | undefined {
return item.price; // deixa caller decidir o que fazer
}
// ✅ Alternativa com Result/Either pattern
type Result<T, E> = { success: true; data: T } | { success: false; error: E };
function getItemPriceResult(item: { name: string; price?: number }): Result<number, string> {
if (item.price === undefined) {
return { success: false, error: "Preço não informado" };
}
return { success: true, data: item.price };
}Distinguindo Política de Negócio vs. Erro de Domínio: O exemplo acima demonstra três abordagens distintas:
- Política de Negócio (
?? 0): Use quando o fallback faz parte das regras de negócio (ex: item sem preço = gratuito) - Delegar Decisão (
number | undefined): Deixa o caller decidir como tratar valores ausentes - Erro Explícito (Result pattern): Força tratamento explícito do caso de erro, evitando “silenciar” problemas de domínio
O resultado de evitar exceções para casos esperados é um código mais claro, eficiente e sem armadilhas ocultas. Em vez de usar try/catch para controlar fluxos normais, prefira estruturas explícitas como if, valores opcionais (std::optional, std::expected em C++23, tl::expected, nullish ??) ou retornos convencionais.
Assim, situações como campo obrigatório não preenchido, busca sem resultado ou divisão por zero prevista são tratadas de forma transparente e previsível, sem sobrecarregar o sistema com o custo e a complexidade das exceções.
Já para eventos realmente excepcionais — como disco cheio, queda de conexão, corrupção de dados ou necessidade de desfazer uma operação crítica — o uso de exceções (throw) é apropriado.
Nesses casos, não há como prever ou contornar o problema apenas com verificações simples, e a exceção serve para interromper o fluxo e sinalizar que algo grave aconteceu, permitindo que o erro seja tratado em um nível superior ou que o programa seja encerrado de forma segura.
Diversas linguagens modernas reforçam essa separação: Rust usa Result<T, E> para erros esperados e reserva panic! para condições irrecuperáveis (bugs, invariantes violadas); Clojure herda exceções da JVM mas favorece erros como dados (mapas, keywords) nas camadas de domínio; TypeScript incentiva o uso de tipos como unknown e alternativas funcionais como Either.
Todas seguem o mesmo princípio: erros previsíveis devem ser tratados como dados, enquanto exceções ficam para situações realmente imprevisíveis. Assim, lançar exceção só quando necessário aproxima o erro da sua origem, evita estados inconsistentes e facilita o diagnóstico, enquanto o uso excessivo só dificulta a manutenção e a clareza do código.
Alternativa correta: retorno explícito de erro
Para casos previsíveis como divisão por zero, a abordagem ideal é usar tipos como std::optional que tornam a possibilidade de falha explícita:
std::optional<int> dividir_seguro(int a, int b) {
if (b == 0) return std::nullopt; // falha previsível
return a / b;
}
// Uso claro e sem exceções
auto media = dividir_seguro(a, b); // retorno explícito
if (!media) { // falha prevista
log("b = 0, usando valor padrão");
} else {
usar(*media);
}No exemplo apresentado acima, vemos que tratar situações esperadas com exceções — como retornar 0 quando o preço está indefinido — prejudica a clareza e a eficiência do código. Isso ocorre porque exceções interrompem o fluxo normal e impactam significativamente otimizações do compilador: impedem marcação de funções com noexcept (essencial para move semântics eficientes na STL), forçam spilling de registradores para memória, e limitam reordenação de instruções que poderiam melhorar o pipeline do processador.
O ideal é reservar exceções para eventos realmente inesperados, como um air-bag que só deve ser acionado em caso de acidente, enquanto validações de domínio e casos previstos devem ser tratados com retornos explícitos, usando estruturas como if, valores opcionais ou operadores como ??.
Linguagens modernas reforçam essa separação ao tratar erros esperados como dados e reservar exceções para situações imprevisíveis. Seguindo essas práticas, seu código permanece limpo, eficiente e fácil de manter, pois cada ferramenta é usada para o propósito correto, evitando surpresas e facilitando o diagnóstico de problemas reais.
Design by Contract e asserções
Beleza, mas como decidir, de forma objetiva, o que é “inesperado”? A resposta clássica vem do Design by Contract (DbC) de Bertrand Meyer.
O Design by Contract (DbC) é um paradigma de desenvolvimento que define um contrato explícito entre um componente e seus clientes, garantindo que ambos entendam as expectativas e as responsabilidades. O DbC estabelece três elementos essenciais:
- Pré-condições: Obrigações que devem ser satisfeitas pelo chamador antes de invocar uma operação.
- Pós-condições: Garantias que a operação fornece quando as pré-condições são atendidas.
- Invariantes: Propriedades que devem ser mantidas ao longo do tempo.
Se a pré-condição de uma função não for atendida, ou seja, se o uso já começa errado (por exemplo, tentar sacar um valor negativo ou maior que o saldo), lançar uma exceção é apropriado, pois indica um erro de uso da interface; por outro lado, se a violação da pré-condição é algo frequente e esperado, como um campo vazio em um formulário, o ideal é tratar esse caso antes mesmo de chamar a função, evitando o uso de exceções para fluxos normais.
O exemplo abaixo em C++ abaixo ilustra como aplicar esse princípio, diferenciando claramente quando lançar exceção por violação de contrato e quando validar previamente:
class Conta {
double saldo_{0}; // invariante: ≥ 0
public:
void sacar(double v) {
if (v <= 0) // pré‑condição violada → erro do usuário
throw std::invalid_argument("valor ≤ 0");
if (v > saldo_) // pré‑condição violada → uso incorreto
throw std::domain_error("saldo insuficiente");
double antigo = saldo_;
saldo_ -= v;
if (saldo_ != antigo - v) // pós‑condição falhou → erro interno
throw std::logic_error("sacar corrompeu saldo");
assert(saldo_ >= 0); // invariante (desligada em release)
}
};Programação com asserções
- O que são: checagens de bugs de desenvolvimento, desativadas em builds release.
- Quando usar: para invariantes internas e estados “impossíveis”.
- Quando não usar: para validar entrada de usuário ou recursos externos (isso é papel de exceção ou valor de retorno).
void push(Buffer& buf, int x) {
assert(!buf.cheio()); // bug se falhar em dev
buf.escreve(x);
}O código apresentado acima ilustra como aplicar, de forma prática, os princípios do Design by Contract (DbC) e o uso de asserções para garantir a robustez do software. Cada tipo de situação exige uma ferramenta adequada: bugs internos, como a quebra de invariantes, devem ser detectados com assert (que só dispara em modo debug); violações de pré-condições, ou seja, quando o usuário utiliza a interface de forma incorreta, são tratadas com exceções específicas como invalid_argument ou domain_error.
Falhas em recursos externos, como problemas de I/O ou falta de memória, são sinalizadas por exceções de runtime (ios_base::failure, bad_alloc); e, finalmente, situações esperadas e frequentes, como um campo opcional vazio, devem ser representadas por tipos como std::optional, std::expected (C++23), tl::expected, boost::outcome ou códigos de status, evitando o uso de exceções para o fluxo normal.
O mini-checklist apresentado resume o contrato em três etapas: primeiro, garantir as pré-condições (validando entradas e lançando exceções quando necessário); segundo, executar o trabalho principal da função; e, por fim, verificar as pós-condições e usar asserções para garantir que as invariantes do objeto foram mantidas.
Assim, o chamador sabe exatamente o que precisa fornecer, a função garante o resultado correto ou lança uma exceção se não puder cumprir, e o objeto permanece sempre em um estado válido. Essa abordagem torna o código mais seguro, previsível e fácil de manter.
Isso fecha, de forma formal, o ciclo começado lá atrás: “exceção para o inesperado, valor para o esperado, assert para o impossível”.
Até aqui vimos que pré‑/pós‑condições e asserções deixam claro o que cada parte deve cumprir — e que exceções só aparecem quando o contrato é quebrado. Mas o inverso também é verdadeiro: quando usamos exceções para controlar o fluxo diário, criamos contratos escondidos que amarram módulos sem ninguém notar.
Quando usamos exceções para controlar o fluxo normal do programa, criamos dependências ocultas entre módulos: o cliente precisa conhecer os tipos de exceção internos do serviço, o que torna o contrato implícito — afinal, as ações a serem tomadas em caso de erro (“se der erro X faça Y”) não aparecem na assinatura da função, mas apenas nos blocos catch espalhados pelo código.
Isso gera fragilidade, pois qualquer alteração nos tipos de exceção ou nas condições que as disparam pode quebrar vários pontos do sistema, como ilustrado no exemplo em C++ abaixo, onde o serviço lança exceções específicas e o cliente é obrigado a capturar cada uma delas individualmente. Observe o exemplo abaixo:
// ❌ Problema: raw pointer + exceções específicas
try {
auto* u = auth.autenticar(user, pass); // Quem é dono de u?
} catch(const UsuarioNaoEncontrado&) { … }
catch(const SenhaInvalida&) { … }
// ✅ Melhor: contrato explícito sem raw pointers
auto resultado = auth.autenticar(user, pass);
if (resultado.has_value()) {
Usuario& u = resultado.value(); // propriedade clara
// ... usar u
} else {
// tratar resultado.error()
}Quando um serviço lança exceções específicas para sinalizar falhas, qualquer alteração nesses tipos de erro obriga o desenvolvedor a revisar e atualizar todos os blocos catch espalhados pelo código cliente.
Isso cria um acoplamento invisível entre módulos: o cliente precisa conhecer detalhes internos do serviço para capturar corretamente cada exceção, tornando a manutenção mais trabalhosa e sujeita a erros. O controle de fluxo baseado em exceções, nesse contexto, esconde contratos importantes e dificulta a evolução segura da API.
Para tornar o contrato explícito e facilitar a manutenção, o C++23 introduziu o std::expected<T, E>, que incorpora o erro ao próprio tipo de retorno da função. Para versões anteriores do C++, alternativas incluem tl::expected (biblioteca header-only), boost::outcome, ou a combinação de std::optional<T> com um código de erro separado. Assim, a assinatura já deixa claro para o usuário todas as possibilidades de sucesso ou falha:
// C++23 - propriedade clara
std::expected<Usuario, ErroAuth>
autenticar(std::string_view user, std::string_view pass);
// Alternativa com smart pointer se necessário
std::expected<std::unique_ptr<Usuario>, ErroAuth>
autenticar(std::string_view user, std::string_view pass);
// Alternativas para C++ < 23
tl::expected<Usuario, ErroAuth> // por valor
outcome::result<Usuario, ErroAuth> // por valor
std::optional<std::unique_ptr<Usuario>> // smart pointer + erro separadoO resultado é um código menos acoplado, mais documentado e mais seguro. O usuário da função já sabe todas as possibilidades de sucesso ou falha, e o compilador força o tratamento via resultado.error().
Contratos de Propriedade: Evitar raw pointers em APIs públicas elimina ambiguidades sobre quem é responsável pela memória. Retorno por valor (
Usuario) transfere propriedade claramente, enquantostd::unique_ptr<Usuario>indica propriedade exclusiva transferida. Ambos evitam vazamentos e dangling pointers que podem surgir comUsuario*quando não está claro se o caller deve fazerdelete.
Testabilidade e caminhos de erro
Na seção anterior, vimos que tornar os contratos explícitos e como é possível reduzir o acoplamento entre módulos e deixa o código mais robusto. Um benefício imediato dessa abordagem é a facilidade de testar: quando o erro é representado como valor de retorno, fica muito mais simples cobrir todos os caminhos possíveis em testes unitários, sem depender de manipulação de exceções.
Isso está totalmente alinhado com o conselho do livro Pragmatic Programmer que diz: “Test your software, or your users will”. Ou seja, “se você não testar seu software, seus usuários vão testar”.
Cenários de erro merecem atenção especial nos testes, pois é justamente no tratamento de falhas que costumam aparecer os bugs mais críticos. Testar apenas o “caminho feliz” não garante a qualidade do sistema. Além disso, garantir que mudanças internas não quebrem o contrato de erro é fundamental para evitar regressões. Testes bem escritos também funcionam como documentação viva, mostrando claramente como o sistema reage a cada tipo de problema.
Por outro lado, quando o tratamento de falhas depende de exceções, surgem desafios práticos. Simular e capturar exceções em testes exige o uso de mocks que lançam erros, além de poluir o código de teste com blocos try-catch ou macros como EXPECT_THROW. Isso pode prejudicar a legibilidade e facilitar a omissão de casos importantes, já que é fácil esquecer de testar um catch específico. O resultado é uma cobertura de testes parcial e menos confiável.
Ao adotar contratos explícitos, como no exemplo em C++ abaixo usando std::expected, o teste se torna mais direto: basta verificar o valor retornado, sem precisar capturar exceções. Isso simplifica o código de teste, aumenta a clareza e garante que todos os ramos — inclusive os de erro — sejam exercitados de forma sistemática.
Assim, além de reduzir o acoplamento, esse padrão melhora a testabilidade e contribui para a manutenção segura do software. Abaixo, vamos ver como testar o código com contratos explícitos e como testar o código com exceções:
Simetria entre Estilos de Contrato de Erro:
// ❌ Testando exceções (mais verboso)
TEST(AuthTest, InvalidPasswordThrows) {
AuthService auth;
EXPECT_THROW(auth.login("user", "wrong"), InvalidPasswordException);
}
// ✅ Testando erros explícitos (mais direto)
TEST(AuthTest, InvalidPasswordReturnsError) {
AuthService auth;
auto result = auth.login("user", "wrong");
ASSERT_FALSE(result.has_value());
EXPECT_EQ(result.error(), AuthError::InvalidPassword);
}Técnicas de Teste Específicas:
-
Mocks que simulam falha
class IServico { public: virtual Dados get(std::string) = 0; }; class MockFalho : public IServico { std::exception_ptr ex_; public: void setFalha(const std::string& msg) { ex_ = std::make_exception_ptr(std::runtime_error(msg)); } Dados get(std::string) override { std::rethrow_exception(ex_); } };Teste foca em como o consumidor reage, sem depender do serviço real.
-
Retorno explícito para casos esperados
struct Resultado { bool ok; std::string erro; Dados dados; }; Resultado processar(const Entrada& in) { if (!valido(in)) return {false,"Entrada inválida",{}}; // ... return {true,"",dados}; } // Teste EXPECT_FALSE(processar(invalido).ok); -
Tipos de erro explícitos – contrato de erro no tipo
// Teste com exceções: precisa capturar tipo específico TEST(FileTest, NonExistentFileThrows) { EXPECT_THROW(lerArquivo("inexistente.txt"), FileNotFoundException); } // Teste com expected: verifica valor e erro diretamente TEST(FileTest, NonExistentFileReturnsError) { auto result = lerArquivo("inexistente.txt"); ASSERT_FALSE(result.has_value()); EXPECT_EQ(result.error(), ErroIO::FileNotFound); EXPECT_THAT(result.error().message(), HasSubstr("inexistente.txt")); } // Alternativas para C++ < 23 tl::expected<Dados,ErroIO> lerArquivo(...); // tl::expected outcome::result<Dados,ErroIO> lerArquivo(...); // boost::outcome -
Testes de propriedade – use frameworks como rapidcheck ou Catch2 generators para iterar entradas aleatórias e garantir:
- “Nenhum input válido gera exceção”.
- “Toda falha retorna erro não‑vazio”.
-
Ambiente de integração controlado – docker de DB que cai, servidor fake que devolve timeouts; reproduz falhas reais sem mexer no prod.
Checklist: Quando Usar Exceções vs. Alternativas
Para facilitar decisões técnicas em governança de código, use este checklist operacional:
✅ Use Exceções (throw) quando:
-
Recurso externo falhou → I/O, rede, sistema de arquivos, BD
throw std::ios_base::failure("Disco cheio")
-
Violação de contrato do chamador → pré-condições quebradas
throw std::invalid_argument("Índice fora dos limites")throw std::domain_error("Saldo insuficiente")
-
Condição irrecuperável → corrupção, invariante violada
throw std::logic_error("Estado interno inconsistente")
-
Falha na alocação de recursos críticos → memória, handles
throw std::bad_alloc()(automático),throw std::runtime_error("Handle pool esgotado")
❌ NÃO use exceções (use alternativas):
-
Erro de domínio esperado →
Result<T,E>,std::expected,std::optionalstd::expected<Usuario, ErroAuth> login(user, pass); // ✅ // throw UsuarioNaoEncontrado(); // ❌ -
Validação de entrada rotineira → códigos de retorno, bool
bool validarEmail(const std::string& email); // ✅ // throw EmailInvalidoException(); // ❌ -
Estado “impossível” interno →
assert(),panic!(debug only)assert(index < size); // ✅ debug // throw std::logic_error("Impossível"); // ❌ production -
Performance crítica → códigos de erro, flags
ErrorCode parseNumber(const char* str, int& result); // ✅ // int parseNumber(const char* str); // throws // ❌
🎯 Regra de Ouro:
“Exceção para o inesperado, valor para o esperado, assert para o impossível”
- Inesperado: Falhas de sistema, violações de contrato, recursos indisponíveis
- Esperado: Validações, buscas sem resultado, parsing que pode falhar
- Impossível: Bugs, invariantes quebradas, estados logicamente inválidos
Referências
- “The Pragmatic Programmer: Your Journey to Mastery” - David Thomas & Andrew Hunt
*Apresenta o princípio “Crash Early” e outras práticas essenciais para programação profissional, incluindo tratamento de erros e resiliência em sistemas. - “Effective Modern C++: 42 Specific Ways to Improve Your Use of C++11 and C++14” - Scott Meyers
Discute técnicas modernas de C++, incluindo o uso correto de exceções e alternativas comostd::optional. - “Programming: Principles and Practice Using C++” - Bjarne Stroustrup
O criador do C++ explica fundamentos da linguagem, incluindo tratamento de erros e quando usar exceções. - “The Rust Programming Language” (Livro Oficial) - Steve Klabnik & Carol Nichols
Explica o sistema deResulteOptiondo Rust, que evita exceções. - “Clojure for the Brave and True” - Daniel Higginbotham
Aborda a filosofia de tratamento de erros em Clojure usando valores e mapas. - “Designing Data-Intensive Applications” - Martin Kleppmann
Discute tolerância a falhas em sistemas distribuídos, complementando o conceito de “graceful failure”. - “Release It!: Design and Deploy Production-Ready Software” - Michael T. Nygard
Ensina padrões como “Circuit Breaker” para lidar com erros em produção. - “Functional Light JavaScript” - Kyle Simpson
Mostra como aplicar conceitos funcionais (incluindo tratamento de erros sem exceções) em JavaScript. - “Domain Modeling Made Functional” - Scott Wlaschin
Usa F# para demonstrar como tipos comoResultpodem modelar erros de forma explícita.
Referências Técnicas e Standards:
-
C++ Core Guidelines
Diretrizes oficiais para C++ moderno, especialmente: -
“Abstraction and the C++ Machine Model” - Bjarne Stroustrup
Discussão técnica sobre overhead de exceções e otimizações do compilador. -
C++23 Standard - Exception Handling (ISO/IEC 14882:2024)
Especificação formal destd::terminate, stack unwinding estd::expected. Seções relevantes: [except] (15), [support.exception] (18.8). -
“Exception Handling Considered Harmful” vs. “Exception Handling Considered Useful”
FAQ oficial do ISO C++ com argumentos balanceados sobre uso de exceções.
💬 Comentários