Como o compilador do Rust funciona?
Introdução
O Rust é famoso por ser uma linguagem que evita muitos erros de memória sem precisar de um coletor de lixo rodando em segundo plano. Mas como ele faz isso? O segredo está no compilador, que passa seu código por várias etapas até virar um programa que o computador entende.
Neste artigo, explicarei de forma simples cada fase desse processo: desde a leitura do código lexing, passando pela análise da estrutura parsing, até a geração do código final pelo LLVM.
Mostrarei como o borrow checker (aquele que reclama dos seus empréstimos de variáveis), as representações intermediárias (com nomes esquisitos como HIR, THIR e MIR) e as otimizações finais trabalham juntos para impedir problemas como dois lugares mexendo na mesma memória ao mesmo tempo data race ou acessar algo que já foi apagado use-after-free.
No fim das contas, a arquitetura em camadas do compilador do Rust permite que ele seja rápido como C, mas com muito mais garantias de que seu programa não vai dar pau por causa de bugs difíceis de achar. Tudo isso graças a essas etapas intermediárias e checagens automáticas que acontecem antes mesmo do programa rodar.
A ponte entre seu código e o computador
Linguagens como C, Go e Rust ficam em um ponto intermediário: elas oferecem mais controle sobre o funcionamento do computador do que linguagens como Java ou C#, mas não são tão próximas do hardware quanto Assembly.
O que as diferencia é a forma como lidam com a memória: em C, o programador tem liberdade total para manipular ponteiros, mas também assume todos os riscos de erros; em Go, existe um coletor de lixo que gerencia a memória automaticamente; já o Rust criou um sistema próprio de “posse e empréstimo” (ownership e borrowing), que previne muitos problemas de memória já na fase de compilação, antes mesmo do programa rodar.
Quando falamos que linguagens como C, Go e Rust são “intermediárias”, isso não quer dizer que existe uma escala fixa entre “baixo nível” (Assembly) e “alto nível” (Java, Python) e que elas ficam sempre no meio.
Na verdade, é só uma forma de dizer que elas misturam características dos dois lados: dão bastante controle sobre o computador (como Assembly), mas também oferecem recursos que facilitam a vida do programador (como Java ou Python).
Por exemplo, C deixa você mexer direto na memória, mas ainda é mais fácil de usar do que Assembly. Go e Rust vão além: trazem recursos modernos, ajudam a evitar erros de memória e, no caso do Rust, permitem escrever código seguro e rápido sem perder desempenho.
Ou seja, “intermediária” é só um jeito de dizer que essas linguagens conseguem equilibrar controle e facilidade, ficando entre o mundo das linguagens super próximas do hardware e o das linguagens super abstratas.
O compilador do Rust
Quando a gente fala de compilador, normalmente ele é dividido em três partes: frontend (a parte que entende o seu código e transforma em uma estrutura de árvore chamada AST), middle-end (que faz otimizações que valem pra qualquer computador) e backend (que transforma tudo em código de máquina pra rodar no seu PC). O Rust segue esse modelo, mas adiciona umas etapas extras só pra garantir que ninguém vai fazer besteira com a memória.
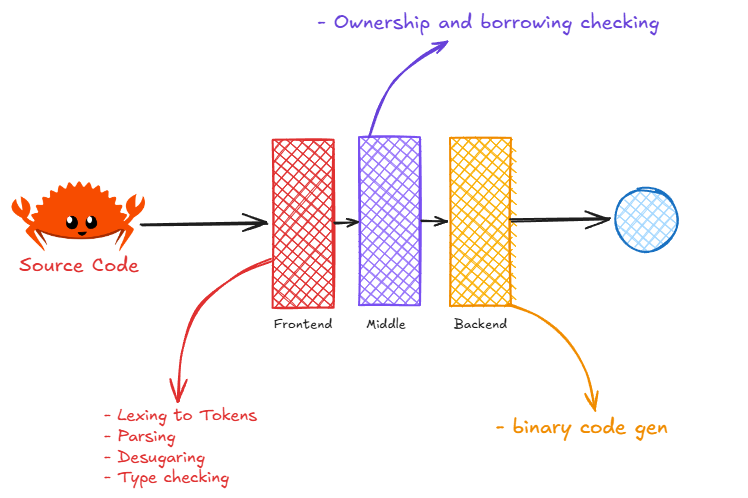
A imagem acima mostra que o compilador do Rust funciona como uma linha de montagem em três etapas: primeiro ele lê e entende seu código (frontend), depois faz uma checagem rigorosa das regras de segurança de memória (middle, onde entra o borrow checker), e por fim transforma tudo em código de máquina que o computador entende (backend); assim, cada parte cuida de um tipo de problema e, no final, seu programa sai rápido e seguro, sem aquelas dores de cabeça típicas de bugs de memória.
Quando você manda o Rust compilar seu arquivo .rs, a primeira coisa que acontece é que o compilador lê o texto e separa tudo em “palavrinhas” chamadas tokens (nomes de variáveis, números, símbolos, etc). Isso é o trabalho do analisador léxico.
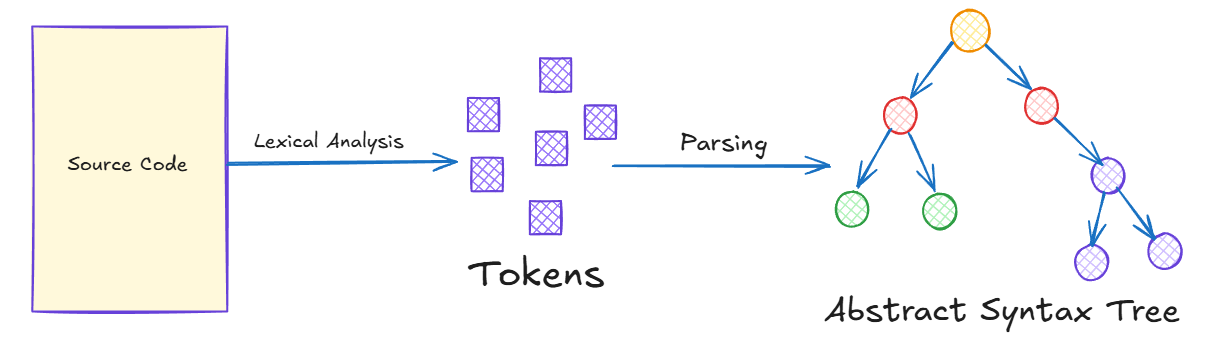
A imagem acima mostra, de forma bem simples, como o compilador do Rust começa a entender seu código: primeiro ele lê o texto do programa e separa tudo em “palavrinhas” chamadas tokens (tipo nomes de variáveis, números, símbolos), e depois organiza esses tokens em uma espécie de árvore que mostra como as partes do seu código se encaixam — como se fosse um esqueleto do programa (a AST).
Ou seja, a figura mostra que o compilador transforma o texto que você escreveu em uma estrutura organizada, facilitando para as próximas etapas encontrarem erros e entenderem o que o programa realmente faz.

Nessa etapa, o compilador também já expande as macros. Ou seja, se você usou algum “atalho” ou macro, ele já troca pelo código real, pra facilitar as próximas fases. Agora vem uma etapa crucial: o compilador pega a AST (que ainda tem comandos de alto nível, tipo o for) e faz um “rebaixamento” lowering: transforma a AST numa versão mais simples chamada HIR (High-level IR).
Essa transformação é fundamental porque a HIR é mais próxima do que a linguagem realmente entende — ela remove a complexidade da sintaxe e deixa tudo mais “quadradinho” para as próximas análises.
Em seguida, ele faz a análise de tipos e gera a THIR (Typed HIR), onde cada pedacinho do código já tem um tipo definido (int, string, etc).
Antes de seguir, o compilador faz uma checagem de segurança chamada unsafety: ele olha a THIR pra garantir que coisas perigosas (tipo mexer direto na memória com ponteiros) só aconteçam dentro de blocos marcados como unsafe. Assim, ele já barra muita coisa errada antes mesmo de virar código de verdade.
A MIR converte o programa num Grafo de Fluxo de Controle (CFG) explícito. Esse grafo permite ao borrow checker rastrear, ao longo de todos os caminhos de execução, o estado de cada valor: possuído, emprestado mutável, emprestado imutável ou movido.
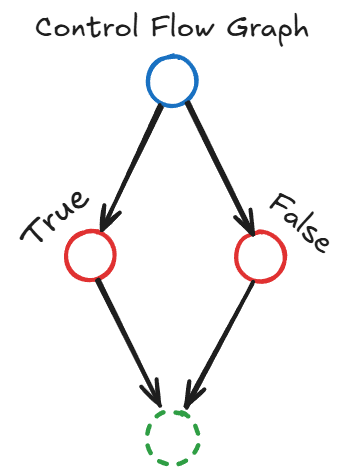
A imagem acima ilustra um exemplo simplificado de um Grafo de Fluxo de Controle (CFG). Nela, o círculo azul no topo representa um ponto de decisão ou condição no seu código (como um if ou match). As setas que partem dele mostram os possíveis caminhos que o programa pode seguir: um para o caso True (círculo vermelho à esquerda) e outro para o caso False (círculo vermelho à direita).
Ambos os caminhos convergem para o círculo verde pontilhado na parte inferior, que simboliza a continuação do programa após a decisão. É essa representação em grafo que permite ao borrow checker do Rust analisar todos os fluxos possíveis do seu código e garantir a segurança da memória em cada um deles, independentemente de qual caminho o programa realmente tomar em tempo de execução.
O Mago da Memória: Entendendo o Borrow Checker
O borrow checker é o coração do sistema de segurança do Rust. Ele funciona como um inspetor rigoroso que analisa cada pedaço do seu código para garantir que ninguém vai mexer na memória de forma perigosa. Usando a MIR como base, o borrow checker rastreia três estados principais para cada valor:
- Possuído (Owned): O valor pertence exclusivamente a uma variável
- Emprestado Imutável (Borrowed Immutable): Outras partes do código podem ler, mas não modificar
- Emprestado Mutável (Borrowed Mutable): Apenas uma parte pode ler e modificar por vez
Caso uma violação ocorra (uso de valor após movimento, criação de dados mutáveis e imutáveis simultâneos, etc.), o compilador rejeita o código. Esse mecanismo previne data races e use‑after‑free sem custo em tempo de execução. O borrow checker é tão eficiente que muitos programadores Rust brincam que ele é “o melhor professor de programação que você já teve” — ele te ensina boas práticas de memória antes mesmo do programa rodar!
Após otimizações em MIR (eliminação de código morto, inlining local, etc.), a IR é traduzida para LLVM IR. A LLVM IR (Low Level Virtual Machine Intermediate Representation) é uma linguagem intermediária de baixo nível, mas independente da arquitetura do processador.
É nela que o Rust traduz tudo o que foi checado e otimizado até aqui, para que a LLVM possa realizar o trabalho pesado de otimização de código. A LLVM IR não é literalmente “entendida pelo processador” — ela serve como uma representação intermediária que o LLVM usa para gerar o código nativo específico da arquitetura de destino (como x86-64, ARM, etc.).
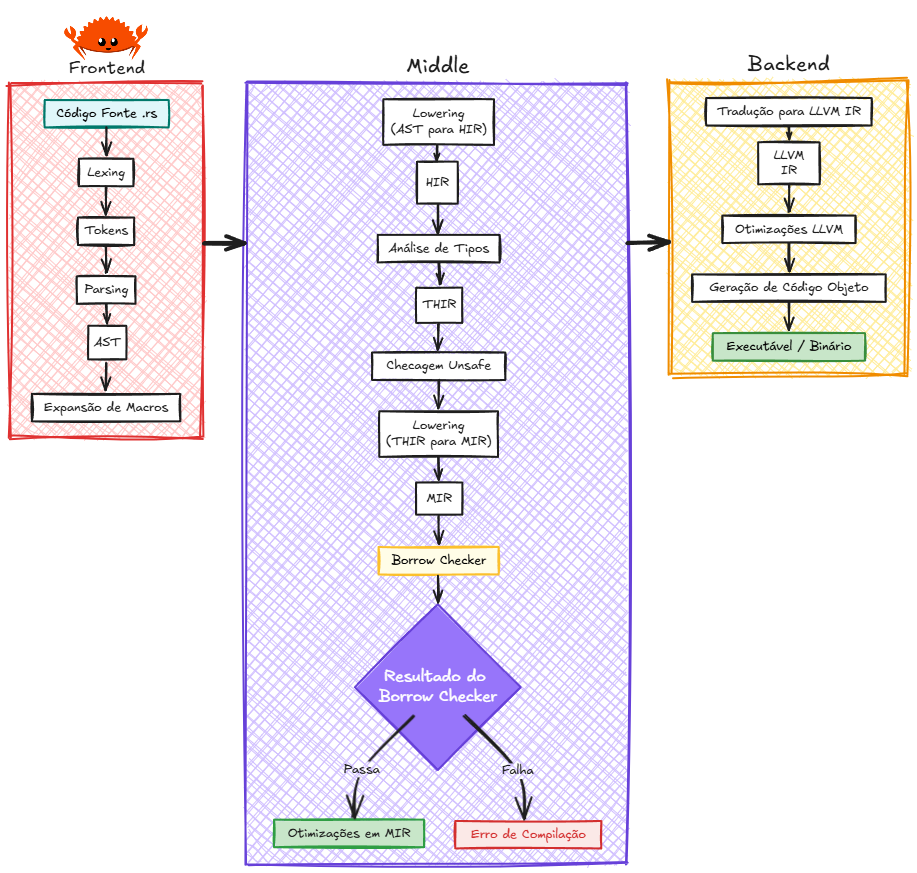
O LLVM aplica otimizações específicas de arquitetura e, por fim, gera código objeto para a plataforma‑alvo, como x86‑64 ou AArch64. Como consequência, um binário Rust é normalmente específico à arquitetura de destino, a menos que se utilize camadas de emulação.
Por que tanta etapa intermediária?
Pense assim: cada IR (representação intermediária) é como um filtro diferente que o compilador usa para checar seu código. Primeiro, a HIR guarda bastante informação para que o compilador possa te dar mensagens de erro detalhadas e entender o contexto do seu programa. Depois, a MIR simplifica tudo, deixando o código mais “quadradinho” e fácil de analisar — é nessa hora que o borrow checker entra em ação, garantindo que ninguém vai mexer na memória de um jeito perigoso.
Essa divisão em camadas faz com que cada parte do compilador só precise se preocupar com um tipo de problema por vez. Isso facilita encontrar erros antes mesmo do programa rodar, sem deixar o código final mais lento.
E, pra fechar com chave de ouro, o Rust entrega a última etapa (gerar o código de máquina de verdade) pro LLVM, que já é um especialista em otimização e velocidade. Assim, o Rust foca em garantir segurança e o LLVM em deixar tudo rápido.
No fim das contas, o compilador do Rust funciona como uma linha de montagem cheia de inspeções: cada etapa checa uma coisa diferente, pegando vários erros que em outras linguagens só apareceriam quando o programa já estivesse rodando (ou pior, em produção!). Por isso, muita gente acredita que esse modelo de “camadas inteligentes” vai ser cada vez mais comum nas linguagens do futuro, juntando robustez e desempenho sem dor de cabeça.
Por fim, vale destacar: linguagens como C e C++ não adotam esse modelo de múltiplas camadas de checagem automática durante a compilação. Nelas, o compilador faz análises mais simples e deixa a maior parte dos cuidados com memória e segurança por conta do programador.
Isso significa que muitos erros perigosos — como acessar memória já liberada, criar data races ou sobrescrever dados sem querer — só aparecem quando o programa já está rodando, e às vezes nem são detectados. O Rust, ao contrário, pega esses problemas antes mesmo do código virar um executável, tornando o desenvolvimento mais seguro sem sacrificar desempenho.
Um estudo de 2002 e publicado em2019 da National Institute of Standards and Technology (NIST) estimou que os erros de software custam à economia dos EUA mais de 59,5 bilhões de dólares anualmente, com uma parcela significativa desses custos vindo de vulnerabilidades de segurança e falhas de memória. A ausência de checagens automáticas em C/C++ contribui para que esses tipos de falhas se tornem uma preocupação constante.
Para não soar como injusto, é necessário dizer que o C++23 trouxe várias novidades para tentar deixar o código mais seguro e moderno, especialmente quando o assunto é evitar bugs de memória — mas sem mudar a linguagem de cabeça pra baixo.
Agora, por exemplo, dá pra declarar de forma explícita quando um objeto começa a existir na memória (com o start_lifetime_as), o que ajuda a evitar aqueles bugs cabeludos que nem os detectores automáticos pegavam. Também ficou mais fácil e seguro conversar com APIs em C sem correr o risco de vazar memória, graças a novos adaptadores de ponteiros inteligentes.
Os containers ganharam versões que evitam acesso fora dos limites (tipo o mdspan para matrizes), e ficou mais prático lidar com erros usando o std::expected, que incentiva o retorno explícito de falhas em vez de depender de códigos mágicos ou variáveis globais.
Até a formatação de texto ficou mais fácil, com funções no estilo Python, e agora dá pra gerar stacktraces portáveis sem gambiarra. Apesar desses avanços, algumas proteções automáticas que o Rust já oferece — como checagem de uso de ponteiros e detecção de data races — ainda não chegaram no C++ (ficaram pra próxima versão).
Ou seja: o C++23 está caminhando para fechar várias brechas históricas e facilitar a vida do programador, mas ainda depende bastante de disciplina e ferramentas externas, enquanto o Rust já faz muita coisa “no automático” para garantir a segurança do seu código.
Enquanto o compilador do Rust atua como um inspetor de qualidade rigoroso, rejeitando qualquer código que possa violar as regras de segurança de memória, o compilador de C/C++ foca em traduzir o código de forma fiel e otimizada. Ele assume que o programador é o responsável por todas as garantias de segurança.
REFERÊNCIAS
- The Rust Reference - The Rust Compiler - A referência oficial do Rust sobre o compilador e a linguagem.
- The Rustc Book - O livro oficial do Rust sobre o compilador.
- Rust Compiler Architecture Overview - Uma visão geral da arquitetura do compilador do Rust.
- LLVM Language Reference Manual - A referência oficial do LLVM sobre a linguagem intermediária.
- C++23 - A referência oficial do C++23.
- Solana Blogs - Onde o artigo se baseou.
- Why is memory safety without GC a big deal in Rust? - Um artigo sobre a importância da segurança de memória sem GC no Rust.
- Overview of the compiler - Uma seção do guia do Rust sobre a geração de código.
- Exploring Dataflow Analysis in the Rust Compiler - Um artigo sobre a análise de fluxo de dados no compilador do Rust.
- Rust Borrow Checker - Uma apresentação sobre o borrow checker do Rust.
💬 Comentários