Prometheus e PromQL
O Prometheus é uma ferramenta open-source de monitoramento de sistemas e aplicações que revolucionou a forma de pensar observabilidade em ambientes distribuídos. Ele coleta e armazena métricas como séries temporais, ou seja, valores numéricos associados a um carimbo de tempo e a pares chave-valor chamados labels.
A potência do Prometheus vem, em parte, da sua linguagem de consulta própria, PromQL, que permite criar consultas complexas para analisar os dados coletados em tempo real. A interface web integrada (Expression browser) facilita visualizar e explorar métricas, possibilitando análises rápidas para identificar tendências e anomalias.
Desenvolvido inicialmente na SoundCloud em 2012 por Julius Volz e equipe, o Prometheus foi projetado para ser simples, eficiente e altamente dimensionável. Em 2016, o projeto foi adotado pela Cloud Native Computing Foundation (CNCF) como o segundo projeto hospedado (logo após o Kubernetes), reforçando sua maturidade e ampla adoção pela comunidade.
Hoje, o Prometheus é um pilar no ecossistema de observabilidade cloud-native, frequentemente usado em conjunto com o Grafana para visualizações avançadas, formando uma poderosa stack de monitoramento.
Tipos de métricas
O Prometheus suporta quatro tipos principais de métricas:
-
Counter (Contador): Métrica cumulativa que apenas aumenta (ou zera). Indicada para quantificar eventos, como número de requisições ou erros. Por exemplo, um contador
http_requests_totalincrementa a cada requisição recebida. Contadores nunca diminuem, exceto quando reiniciados. Consultas comuns envolvem a taxa de aumento usando funções comorate()ouincrease(), calculando, por exemplo, quantas requisições por segundo ocorreram em determinado intervalo. -
Gauge (Indicador): Métrica que representa um valor em um instante, podendo tanto aumentar quanto diminuir. Indicado para valores como utilização de CPU, memória ou tamanho de fila – que sobem e descem livremente. Não possui limite mínimo ou máximo fixo. Funções como
avg_over_time(),min(),max()esum()são frequentemente aplicadas sobre gauges para obter médias, mínimos, máximos ou somas ao longo do tempo. -
Histogram (Histograma): Métrica que contabiliza a distribuição de valores observados em buckets (faixas) predefinidos. É muito utilizada para medir latências (e.g., duração de requisiões) ou outros valores cuja distribuição importa. O Prometheus implementa histogramas através de vários contadores – um por bucket – além de contadores especiais para total de observações (
_count) e soma dos valores (_sum). Consultas tipicamente usamhistogram_quantile()para extrair percentis a partir dos buckets e funções comorate()ouincrease()nos contadores para ver taxas. -
Summary (Sumário): Métrica similar ao histograma, mas os cálculos de percentis e médias são feitos pelo próprio alvo instrumentado. O summary fornece diretamente percentis (por exemplo, latência p95) e contagens/agregados para um conjunto de observações. Entretanto, summaries têm a limitação de não poderem ser agregados facilmente entre múltiplas instâncias (diferente dos histogramas). Em geral, histogramas são preferidos para métricas de latência quando se quer combinar valores de várias fontes, enquanto summaries podem ser úteis para percentis muito específicos em instâncias isoladas.
Use Histogramas quando precisar agregar latências de múltiplas instâncias e calcular percentis globais. Use Sumários quando os percentis calculados no cliente são suficientes e a agregação não é necessária.
Além desses tipos principais, o Prometheus expõe métricas especiais de estado – por exemplo, a métrica interna up indica se um determinado alvo foi coletado com sucesso (valor 1) ou não (0). Essa métrica é muito útil para monitorar disponibilidade de serviços: se um endpoint monitorado ficar indisponível, up{instance="endpoint:porta"} == 0 sinaliza falha. Vale notar que não existe um “tipo” separado para essas métricas de saúde; elas normalmente são gauges (0 ou 1) usadas para esse propósito.
Monitoramento pull vs push
Para entender pull vs push, imagine cuidar de plantas: no modelo pull você vai todo dia verificar se precisam de água; no modelo push as próprias plantas enviam um sinal quando precisam ser regadas. Tecnicamente, no monitoramento pull um sistema central (como o Prometheus) consulta periodicamente os alvos para coletar métricas – ele “puxa” as informações. Já no monitoramento push, os próprios alvos enviam (empurram) as métricas para um coletor central sem serem solicitados.
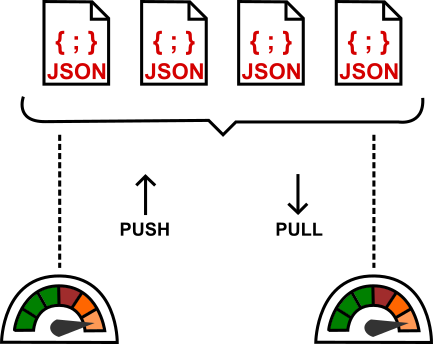
No Prometheus, prevalece o modelo pull. O servidor Prometheus periodicamente faz scrape (raspagem) dos dados de cada alvo exportador via HTTP, no endpoint padrão /metrics. Cada scrape coleta o valor atual de todas as séries expostas naquele alvo.
Os alvos podem ser aplicações instrumentadas que expõem suas métricas diretamente, ou exporters (exportadores) que traduzem métricas de sistemas externos para o formato do Prometheus.
Assim, o Prometheus obtém em intervalos regulares (por padrão a cada 15s) as métricas atuais de cada serviço, armazenando-as localmente.
Na imagem acima, a comparação dos modelos de coleta: à esquerda, no modo push os clientes enviam suas métricas proativamente a um gateway; à direita, no modo pull o Prometheus consulta cada cliente periodicamente. O modelo pull tem vantagens em simplicidade e confiabilidade – se um serviço cair, o Prometheus sabe (a métrica up fica 0) e não depende de buffers intermediários.
Já o modelo push pode ser útil para casos específicos, como jobs de curta duração ou ambientes onde não é possível expor um endpoint (nesses casos usa-se o Pushgateway, discutido adiante). Em suma, o Prometheus, por padrão, não recebe métricas ativamente; ele mesmo vai coletá-las, evitando sobrecarga nos aplicativos monitorados e detectando automaticamente indisponibilidades.
Arquitetura do Prometheus
A arquitetura do Prometheus foi concebida para facilitar a coleta de dados de múltiplas fontes de forma confiável e distribuída. O coração do sistema é o Prometheus Server principal, responsável por agendar e realizar as coletas (scrapes) de cada alvo monitorado e armazenar as séries temporais resultantes localmente.
A configuração dessas coletas é definida em um arquivo YAML (geralmente prometheus.yml), especificando jobs e targets – por exemplo, “coletar métricas do serviço X na URL Y a cada 15 segundos”. A figura abaixo (extraída da documentação oficial) ilustra a arquitetura e os componentes do ecossistema Prometheus:
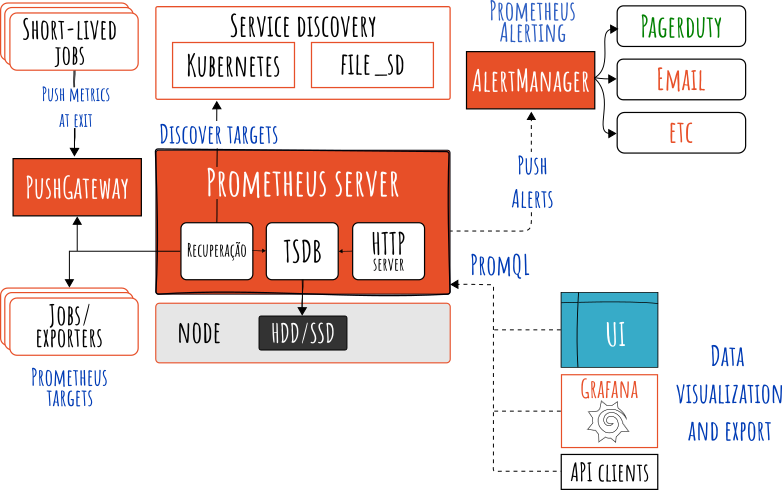
Em resumo, o fluxo é: o Prometheus coleta (pull) métricas dos jobs instrumentados, diretamente dos serviços ou via um componente intermediário de push para jobs efêmeros. Todos os samples coletados são armazenados localmente no banco de dados de séries temporais embutido (TSDB).
Regras definidas podem ser executadas continuamente sobre esses dados – seja para gravar novas séries agregadas (recording rules) ou para acionar alertas. Os alertas gerados pelo Prometheus são então enviados para o Alertmanager processar. Por fim, ferramentas de visualização como o Grafana podem consultar o Prometheus para exibir dashboards das métricas coletadas.
O ecossistema Prometheus possui diversos componentes (muitos opcionais) que interagem nessa arquitetura:
- Servidor Prometheus – o servidor principal que coleta e armazena as métricas e processa consultas PromQL.
- Bibliotecas cliente – usadas para instrumentar código de aplicações (expondo métricas via /metrics). Há libs oficiais em Go, Java, Ruby, Python, etc.
- Exporters – programas externos que coletam métricas de serviços ou sistemas terceiros (bancos de dados, servidores web, sistemas operacionais) e as expõem no formato Prometheus. Exemplos: Node Exporter (métricas de sistema Linux), Blackbox Exporter (monitoramento de endpoints externos), etc.
- Pushgateway – gateway para receber métricas pushed por aplicativos de curta duração ou ambientes onde não dá para o Prometheus puxar diretamente.
- Alertmanager – componente responsável por receber alertas enviados pelo Prometheus e gerenciar o envio de notificações (email, Slack, PagerDuty etc.), realizando agrupamento, deduplicação e silenciamento conforme configurado.
- Ferramentas de suporte – englobam utilitários de linha de comando (como o promtool), exportadores de terceiros, dashboards pré-configurados, entre outros, que facilitam operar e integrar o Prometheus.
Essa arquitetura descentralizada (com coleta pull e componentes distintos) torna o Prometheus especialmente adequado a ambientes modernos com microsserviços e orquestração de contêineres (Docker, Kubernetes).
Ele foi projetado para funcionar de forma autônoma em cada nó (cada servidor Prometheus é independente, sem dependência de armazenamento distribuído), privilegiando confiabilidade mesmo durante falhas de rede ou de outros serviços. Em caso de problemas graves na infraestrutura, você ainda consegue acessar métricas recentes localmente no Prometheus, que atua como fonte de verdade para diagnosticar incidentes.
Labels e Samples
No Prometheus, labels (rótulos) e samples (amostras) são conceitos-chave para organizar os dados monitorados.
Uma analogia simples: imagine um guarda-roupa onde cada roupa tem etiquetas indicando cor, tamanho e tipo. Essas etiquetas ajudam a encontrar rapidamente, por exemplo, “camisetas verdes tamanho M”.
Da mesma forma, no Prometheus cada métrica pode ter vários labels (chave=valor) que a qualificam.
Por exemplo, uma métrica app_memory_usage_bytes poderia ter labels como host="servidor1" e region="us-east". Assim podemos filtrar/consultar “uso de memória no servidor1” apenas buscando por host="servidor1".
Os labels permitem um modelo de dados multidimensional – ou seja, uma mesma métrica (ex: http_requests_total) é armazenada separadamente para cada combinação de labels (rota="/login", método=“GET”, código=“200”, etc.). Isso enriquece as análises, pois podemos agregar ou dividir métricas por essas dimensões conforme necessário.
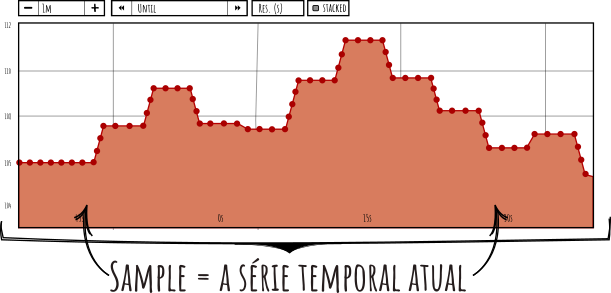
Já os samples são as unidades de dado coletadas ao longo do tempo – cada medição individual de uma métrica em um determinado instante.
Voltando à analogia, se pedíssemos a cada criança numa pesquisa que escolhesse 3 balas, as balas escolhidas por cada criança seriam uma amostra da preferência de balas.
No contexto do Prometheus, a cada scrape o valor de cada métrica coletada é um sample (com timestamp e valor). Esses samples ficam armazenados como uma série temporal etiquetada, permitindo ver a evolução daquele valor no tempo.
Por exemplo, considere a métrica gauge node_cpu_usage com label host. Para cada host monitorado, teremos uma série separada, e a cada intervalo de coleta obtemos um sample novo do uso de CPU daquele host. Assim, podemos consultar a série para ver como a CPU variou ao longo de um dia inteiro para cada máquina.
Exemplo de séries temporais no Prometheus: cada ponto representa um sample (valor observado) etiquetado por instância ou outra dimensão, armazenado em sequência temporal.
Em resumo, labels fornecem contexto (quem, onde, o quê) e samples fornecem o valor numérico no tempo. Essa combinação é o que torna o Prometheus poderoso para agregar métricas semelhantes e, ao mesmo tempo, permitir recortes por dimensão. Vale ressaltar a importância de escolher labels com cardinalidade controlada – ou seja, evitar labels que possam assumir valores extremamente variados (como IDs únicos, URLs completas ou timestamps).
Nota: Labels com variação descontrolada podem causar uma explosão de séries e sobrecarregar o Prometheus, conforme discutiremos em melhores práticas.
Instalação
Existem diversas maneiras de instalar e executar o Prometheus. Aqui vou demonstrar uma configuração simples usando Docker e Docker Compose, incluindo o Grafana e uma ferramenta de simulação de métricas chamada PromSim (útil para testes). Essa stack de exemplo traz:
- Prometheus – servidor de métricas.
- Grafana – para dashboards e visualização.
- PromSim – um simulador que expõe métricas aleatórias para exercitar o Prometheus.
Comece criando um arquivo docker-compose.yml com o seguinte conteúdo:
version: "3"
services:
prometheus:
image: prom/prometheus:latest
container_name: prometheus
ports:
- "9090:9090"
volumes:
- "./prometheus.yml:/etc/prometheus/prometheus.yml"
depends_on:
- promsim
grafana:
image: grafana/grafana:latest
container_name: grafana
ports:
- "3000:3000"
promsim:
image: sysdigtraining/promsim:latest
container_name: promsim
ports:
- "8080:8080"No mesmo diretório, crie o arquivo de configuração prometheus.yml para o Prometheus:
global:
scrape_interval: 15s
evaluation_interval: 15s
scrape_configs:
- job_name: "promsim"
static_configs:
- targets: ["promsim:8080"]Esse arquivo define que o Prometheus fará scrape a cada 15s (scrape_interval) e avalia regras na mesma frequência (evaluation_interval). Em scrape_configs, temos um job chamado “promsim” que coleta métricas do endereço promsim:8080 (nosso container PromSim simulando um alvo de métricas). Agora suba os serviços:
docker-compose up -dIsso iniciará os containers Prometheus, Grafana e PromSim em segundo plano. Após o start, acesse o Grafana em http://localhost:3000 (usuário admin, senha admin padrão). No Grafana, adicione o Prometheus como fonte de dados: vá em Configuration (engrenagem) > Data Sources, adicione nova fonte do tipo Prometheus com URL http://prometheus:9090 (que, devido ao Docker Compose, resolve para o container do Prometheus).
Feito isso, você já pode importar ou criar painéis Grafana usando as métricas do Prometheus (inclusive as geradas pelo PromSim). O PromSim estará expondo várias métricas aleatórias – por exemplo, simulando CPU, memória, requisições – permitindo testar consultas e alertas sem precisar de uma aplicação real por trás. Para mais detalhes do PromSim, veja a documentação oficial.
Caso queira rodar apenas o Prometheus isoladamente, basta executar o container oficial: docker run -p 9090:9090 prom/prometheus. Depois acesse http://localhost:9090 para abrir a UI nativa do Prometheus:
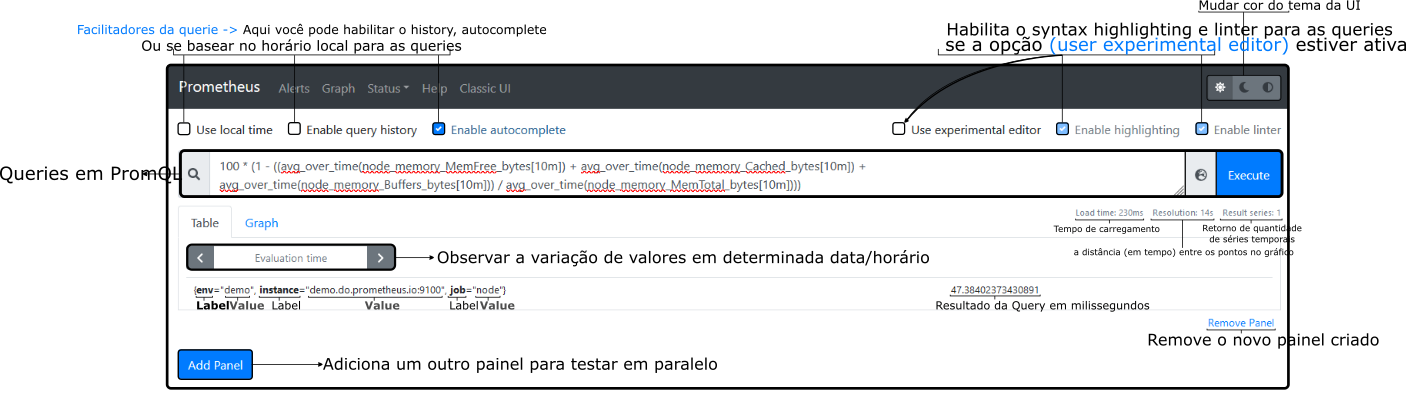
A interface web padrão do Prometheus inclui os seguintes menus no topo:
- Alerts: lista os alertas ativos e suas informações. Mostra também alertas pendentes e silenciados.
- Graph: permite rodar consultas PromQL e visualizar o resultado em formato gráfico (ou tabela). É útil para explorar interativamente as métricas.
- Status: informações sobre o status do servidor Prometheus – memória usada, número de séries ativas, status das coletas, etc.
- Targets (na seção Status): mostra todos os alvos configurados e se a coleta está OK (up) ou falhou.
- Service Discovery (também em Status): lista os serviços descobertos via mecanismos dinâmicos (Kubernetes, DNS, etc.).
- Help: link para documentação e ajuda do Prometheus.
Além disso, logo abaixo dos menus, a UI oferece algumas opções e campos importantes:
- Time range e refresh: controles para selecionar o intervalo de tempo da consulta e atualizar automaticamente.
- Use local time: alterna entre exibir os timestamps no seu fuso horário local ou em UTC.
- Query history: opção para habilitar histórico das consultas feitas (facilita repetir queries recentes).
- Autocomplete: opção para habilitar auto-completar de métricas e funções no campo de consulta.
- Campo de consulta PromQL: onde você escreve a expressão a ser consultada. O Prometheus traz sugestões enquanto você digita (se autocomplete ligado).
- Botões Execute / Reset: para executar a consulta ou limpar o campo.
- Aba Graph / Table: seleciona se o resultado será plotado em um gráfico ou mostrado como tabela bruta de valores.
- Evaluation time: permite fixar um timestamp específico para avaliar a query (por padrão é “now”, mas você pode ver valores históricos escolhendo um horário passado).
Dica: a UI do Prometheus é ótima para explorar e depurar métricas rapidamente, mas para dashboards permanentes e mais bonitos geralmente usamos o Grafana. O Grafana se conecta ao Prometheus via API e permite combinar múltiplas consultas em gráficos customizados.
Configuração
Após instalar, o principal arquivo a ajustar é o de configuração do Prometheus (prometheus.yml). Nele definimos os parâmetros globais, jobs de scrape, regras de alerta, etc. Vamos examinar a estrutura básica e algumas customizações comuns. Um exemplo mínimo de prometheus.yml poderia ser:
global:
scrape_interval: 15s
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ['localhost:9090']Nesse caso, definimos um intervalo global de scrape de 15s e um job para monitorar o próprio Prometheus (expondo métricas em localhost:9090). Para monitorar outras aplicações, adicionamos novos blocos em scrape_configs. Por exemplo, para monitorar uma aplicação web rodando na porta 8080 de um host chamado my-app:
scrape_configs:
- job_name: 'my-app'
static_configs:
- targets: ['my-app:8080']Isso instruirá o Prometheus a coletar periodicamente métricas em http://my-app:8080/metrics. Podemos repetir o processo para cada serviço ou componente que queremos incluir, definindo um job_name descritivo e a lista de endpoints (targets).
Para ambientes com muitos alvos ou infraestrutura dinâmica, é inviável gerenciar esses targets manualmente. Nesses casos, o Prometheus oferece integrações de Service Discovery (Kubernetes, AWS EC2, Consul, DNS, etc.) e também o file-based discovery (descoberta via arquivos).
Este último permite apontar para um ou mais arquivos JSON externos contendo a lista de targets. Assim, ferramentas externas ou scripts podem atualizar esses arquivos conforme os serviços mudam, e o Prometheus percebe as alterações automaticamente. Por exemplo, poderíamos alterar o job acima para usar arquivo:
scrape_configs:
- job_name: 'my-app'
file_sd_configs:
- files:
- /etc/prometheus/targets/my-app.jsonE no arquivo /etc/prometheus/targets/my-app.json colocar algo como:
[
{
"labels": {
"job": "my-app",
"env": "production"
},
"targets": [
"my-app1:8080",
"my-app2:8080"
]
}
]Nesse JSON, especificamos dois targets (dois instâncias da aplicação my-app) e também atribuímos labels adicionais a essas instâncias (env: production, por exemplo). Assim, se futuramente adicionarmos my-app3:8080, basta atualizar o JSON – o Prometheus recarrega periodicamente ou quando o arquivo muda. Esse método facilita escalabilidade e automação da configuração de alvos.
Outro ponto de configuração importante é a retenção de dados. Por padrão, o Prometheus guarda as séries temporais localmente por 15 dias. Em ambientes de produção, pode ser necessário ajustar esse período.
Você pode definir a flag de inicialização --storage.tsdb.retention.time (ou configurar no serviço) para algo maior, por exemplo 30d para reter ~1 mês de métricas. Tenha em mente que aumentar a retenção aumenta proporcionalmente o consumo de disco e memória.
Também é possível limitar por tamanho de disco (--storage.tsdb.retention.size), se preferir. Caso precise de retenção muito longa (meses/anos), é recomendável integrar com soluções de armazenamento remoto em vez de manter tudo no Prometheus (falaremos disso em Melhores Práticas).
Exemplo de definição de retenção no systemd (ExecStart):
/opt/prometheus/prometheus \
--config.file=/opt/prometheus/prometheus.yml \
--storage.tsdb.retention.time=30dNota: O formato aceita unidades como
h,d,w,y. Você também pode usar a opção--storage.tsdb.retention.sizepara definir um tamanho máximo (por ex:50GB), o que ocorrer primeiro (tempo ou tamanho) aciona a limpeza de dados antigos.
Em instalações via pacote ou container, normalmente a estrutura de diretórios do Prometheus é assim:
/opt/prometheus/
├── prometheus (binário)
├── promtool (binário utilitário)
├── prometheus.yml (configuração)
├── consoles/ (arquivos HTML da UI "classic")
├── console_libraries/ (bibliotecas JS para consoles)
└── data/ (armazenamento local das séries temporais)A pasta data/ merece destaque – ali ficam todos os dados das métricas coletadas. Abordaremos sua estrutura interna na seção “Under the Hood”.
Em resumo, após instalar, você deve editar o
prometheus.ymlpara incluir todos os targets que deseja monitorar (seja listando estaticamente ou via mecanismos dinâmicos) e ajustar parâmetros globais (intervalos, regras, retenção).
Depois reinicie o serviço/container do Prometheus para aplicar as alterações. Para validar se a sintaxe do arquivo está correta antes de reiniciar, podemos usar o promtool conforme abaixo.
🔍 Instrumentação
A instrumentação é o processo de inserir coleta de métricas em sistemas e aplicações. No contexto Prometheus, podemos dividir em dois tipos:
📊 Instrumentação direta (na aplicação)
Significa instrumentar o próprio código da aplicação ou serviço para expor métricas de negócio ou de desempenho relevantes. Você adiciona pontos de métrica no código (counters, gauges, etc.) usando uma biblioteca cliente do Prometheus.
Assim, a própria aplicação passa a expor um endpoint /metrics com dados em tempo real sobre si mesma (latência de requisições, uso de memória interno, tamanho de fila, etc.).
Essa abordagem dá controle granular – os desenvolvedores escolhem o que medir – e tende a fornecer métricas altamente específicas e úteis para diagnosticar o comportamento da aplicação.
🔄 Instrumentação indireta (via exporters)
Refere-se a coletar métricas de sistemas externos ou legados através de componentes intermediários chamados exporters. Em vez de modificar o sistema alvo, você roda um exporter que coleta informações daquele sistema (geralmente via APIs existentes, comandos ou leitura de arquivos) e as expõe no formato Prometheus.
O Prometheus então faz scrape nesse exporter. Essa abordagem é comum para: sistemas operacionais, bancos de dados, servidores web, ou qualquer software que não tenha suporte nativo ao Prometheus.
Por exemplo, há exporters para MySQL, PostgreSQL, Apache/Nginx, Redis, entre muitos outros, que traduzem métricas desses sistemas para o formato esperado.
Ambos os tipos são importantes. A instrumentação direta fornece métricas sob medida da aplicação (por exemplo, quantas transações processou, quantos usuários ativos, etc.), enquanto a indireta garante visibilidade de componentes de infraestrutura e softwares de terceiros sem precisar alterar eles.
A seguir, veremos exemplos de instrumentação indireta (principais exporters) e de instrumentação direta em algumas linguagens.
Instrumentação indireta: Exporters
Ecossistema nativo: O Prometheus já oferece diversos exporters oficiais ou mantidos pela comunidade para sistemas populares. Alguns exemplos:
-
Node Exporter (Linux): Coleta métricas de sistema operacional Linux – CPU, memória, disco, rede, entropia, stats de kernel, etc. É imprescindível para monitorar VMs ou servidores bare metal. Basta executar o binário do node_exporter no host; ele abre :9100/metrics com dezenas de métricas padronizadas (cpu_seconds_total, node_filesystem_usage_bytes, etc.). Essas métricas dão uma visibilidade completa do estado do host, permitindo identificar gargalos de recurso.
-
Windows Exporter (Windows): Equivalente para plataformas Windows (antigo WMI exporter). Coleta CPU, memória, disco, contadores do Windows, etc., expondo em :9182/metrics (porta padrão). Assim, ambiente heterogêneos também podem ser monitorados.
-
Blackbox Exporter: Útil para monitorar externamente a disponibilidade de serviços. Ele executa probes do tipo ICMP (ping), HTTP(S), DNS, TCP, etc., simulando a experiência do usuário externo. Você configura módulos de probe (ex: checar HTTP 200 em determinada URL dentro de 2s) e o Prometheus chama o Blackbox passando o alvo a testar. Se a resposta falha ou excede tempo, métricas como
probe_success=0 ouprobe_duration_secondsindicam problema. É excelente para monitorar uptime de sites e endpoints de fora para dentro. -
Exporters de aplicações: Há muitos: PostgreSQL exporter, Redis exporter, JMX exporter (Java), SNMP exporter (equipamentos de rede), etc. Em geral, se você usar alguma tecnologia popular, provavelmente já existe um exporter pronto (a documentação oficial lista dezenas: Exporters e integrações).
Como usar exporters? Normalmente é executar o binário do exporter próximo do serviço alvo, e então adicionar um job no
prometheus.ymlapontando para o endpoint do exporter. Por exemplo, para Node Exporter em várias máquinas, você rodaria node_exporter em cada host (porta 9100) e adicionaria algo como:
scrape_configs:
- job_name: 'node'
static_configs:
- targets: ['host1:9100', 'host2:9100', ...]Assim o Prometheus coletará as métricas de cada máquina. Cada métrica virá automaticamente com labels como instance="host1:9100" e outras específicas (o Node Exporter adiciona label job="node" e por vezes labels como cpu="0" para métricas por CPU, etc.).
Em resumo, a instrumentação indireta via exporters é fundamental para trazer para o Prometheus dados de componentes que não expõem nativamente as métricas. É um jeito de bridge (ponte) entre sistemas legados e o moderno mundo do Prometheus.
Configuração Avançada
Discovery Dinâmico e Relabeling
Em ambientes modernos com infraestrutura dinâmica (Kubernetes, cloud, microsserviços), configurar targets manualmente no prometheus.yml torna-se inviável. O Prometheus oferece mecanismos de Service Discovery que permitem descobrir automaticamente alvos para monitoramento, e o Relabeling permite transformar dinamicamente essas descobertas durante o processo de configuração.
Service Discovery
O Prometheus suporta diversos mecanismos de descoberta automática:
- Kubernetes: Descobre pods, serviços, endpoints automaticamente baseado em labels e anotações.
- AWS EC2: Encontra instâncias EC2 baseado em tags.
- Consul: Usa o Consul como fonte de verdade para serviços.
- DNS: Resolve nomes DNS para descobrir alvos.
- File-based: Lê targets de arquivos JSON/YAML que podem ser atualizados externamente.
Exemplo de discovery Kubernetes:
scrape_configs:
- job_name: 'kubernetes-pods'
kubernetes_sd_configs:
- role: pod
relabel_configs:
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_scrape]
action: keep
regex: true
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_path]
action: replace
target_label: __metrics_path__
regex: (.+)
- source_labels: [__address__, __meta_kubernetes_pod_annotation_prometheus_io_port]
action: replace
regex: ([^:]+)(?::\d+)?;(\d+)
replacement: $1:$2
target_label: __address__Relabeling
O relabeling é uma funcionalidade poderosa que permite transformar labels, nomes de targets, endereços e outros metadados durante o processo de discovery. É fundamental para:
- Filtrar targets indesejados (ex: excluir pods de teste)
- Adicionar/remover labels dinamicamente
- Transformar endereços (ex: mascarar IPs internos)
- Agrupar targets logicamente
Exemplo prático de relabeling:
relabel_configs:
# Manter apenas pods com annotation prometheus.io/scrape=true
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_scrape]
action: keep
regex: true
# Extrair namespace como label
- source_labels: [__meta_kubernetes_namespace]
action: replace
target_label: namespace
# Adicionar label de ambiente baseado no namespace
- source_labels: [namespace]
regex: 'prod-.*'
replacement: 'production'
target_label: environment
# Remover porta padrão se não especificada
- source_labels: [__address__]
regex: '(.+):8080'
target_label: instance
replacement: '$1'
# Filtrar targets que começam com 'test'
- action: drop
source_labels: [__meta_kubernetes_pod_name]
regex: 'test.*'Casos de uso comuns:
- Filtros de ambiente: Manter apenas pods de produção, excluindo dev/test
- Mascaramento de dados sensíveis: Remover IPs internos ou informações de debug
- Agregação por labels: Agrupar targets por região, datacenter, time
- Normalização de nomes: Padronizar nomes de instâncias ou serviços
Importante: O relabeling é aplicado antes do scrape, então você pode usar
__meta_*labels (metadados do discovery) para tomar decisões sobre quais targets monitorar e como rotulá-los.
PromQL: Os Fundamentos
PromQL é a linguagem de consulta poderosa usada pelo Prometheus para extrair dados de métricas e configurar alertas. Seu principal objetivo é possibilitar a análise e monitoramento de métricas (como requisições HTTP por segundo ou a média de utilização de CPU por servidor) por meio de expressões que definem cálculos específicos.
O PromQL suporta funções matemáticas, operações booleanas e de comparação, além de agrupamento de dados e agregações. Ela também conta com recursos avançados, como subconsultas e funções de análise temporal.
As consultas PromQL podem ser executadas através da interface web do Prometheus, de APIs ou de bibliotecas de clientes. Em resumo, a PromQL é essencial para monitorar e analisar o desempenho de sistemas com eficiência e precisão.
A linguagem também possibilita a criação de gráficos e painéis de visualização para métricas, utilizando ferramentas como o Grafana. Desta forma, a PromQL se mostra fundamental para obter insights rápidos sobre o comportamento de aplicações e infraestruturas.
Nesta seção, vamos explorar os fundamentos da PromQL — incluindo seletores, tipos de vetores e operadores básicos — e demonstrar como criar consultas simples para analisar dados de métricas.
Time Series Database (TSDB)
O Prometheus armazena os dados em um formato binário chamado TSDB (Time Series Database). O TSDB é um banco de dados de séries temporais otimizado para armazenar métricas de forma eficiente.
Para simplificar o entendimento, imagine que você tem um diário onde registra, todos os dias e nos mesmos horários, informações como a temperatura do ar, velocidade do vento e pressão atmosférica.
Essas informações são armazenadas em ordem cronológica (por tempo) e podem ser consultadas para ver como variam ao longo do tempo. Essa é a essência de um banco de dados de série temporal: armazenar e consultar dados que possuem uma dimensão temporal.
Monitorar métricas a partir de um banco de dados de séries temporais traz várias vantagens:
- Análise histórica: Por armazenar dados em ordem cronológica, é possível analisar tendências e padrões ao longo do tempo. Isso ajuda a entender como o desempenho do sistema evolui e identificar tendências que possam indicar problemas futuros.
- Identificação de problemas: Com dados históricos, podemos investigar incidentes passados para identificar causas raiz de problemas de desempenho ou disponibilidade.
- Alertas baseados no tempo: Dados históricos permitem criar alertas que consideram tendências temporais, como alertar quando um recurso tem desempenho abaixo do normal em horários específicos ou quando há tendências de crescimento preocupantes.
- Armazenamento escalável: Bancos de dados de séries temporais são projetados para lidar com grandes volumes de dados e escalar horizontalmente, permitindo armazenar métricas sem perda de desempenho.
- Integração com outras ferramentas: A maioria das ferramentas de monitoramento suporta a coleta de dados de TSDBs, facilitando a integração com diversos sistemas de análise e observabilidade.
Em resumo, usar um banco de dados de série temporal permite coletar, armazenar e analisar dados de métricas de desempenho ao longo do tempo, possibilitando identificar problemas, tendências e padrões com facilidade.
O PromQL (Prometheus Query Language) é a linguagem usada para consultar essas métricas armazenadas no Prometheus. Com o PromQL, os usuários criam consultas complexas para extrair informações acionáveis das métricas. Algumas capacidades importantes do PromQL incluem:
- Funções de agregação: Permitem resumir dados ao longo do tempo ou por categorias, como média, soma, máximo e mínimo. Por exemplo, podemos usar
avg()para calcular a média de uma métrica ao longo de um período. - Funções de filtragem: Permitem selecionar subconjuntos das métricas com base em critérios. Por exemplo, podemos usar seletores para filtrar por rótulos (labels) específicos, como pegar apenas métricas de um serviço ou data center específico.
- Funções de transformação: Permitem transformar os dados brutos em valores mais úteis. Por exemplo, a função
rate()calcula a taxa de mudança de um contador (como número de requisições por segundo) a partir da diferença entre dois pontos no tempo.
PromQL também suporta operações matemáticas básicas (adição, subtração, multiplicação e divisão) para combinar métricas ou ajustar seus valores. Além disso, permite o uso de operadores lógicos (como and e or) para combinar expressões e criar consultas ainda mais complexas.
Recursos avançados, como uso de rótulos (labels) para selecionar séries específicas e subconsultas aninhadas, tornam a PromQL uma linguagem poderosa e flexível. A seguir, exploraremos em detalhes esses conceitos e como utilizá-los na prática.
Seletores de métricas
Os seletores em PromQL funcionam como filtros que permitem escolher uma ou mais séries de métricas específicas para consulta. Existem dois tipos principais de seletores:
- Seletor por nome de métrica: Seleciona séries pelo nome da métrica. Por exemplo,
http_requests_totalretorna todas as séries temporais cuja métrica tenha esse nome. - Seletor por label: Seleciona séries com base em um ou mais labels (rótulos) e seus valores. Por exemplo, se uma métrica
http_requests_totalpossui os labelsmethodehandler, podemos filtrar pelas séries ondemethod="GET"ehandler="/api/v1/users"escrevendo:
http_requests_total{method="GET", handler="/api/v1/users"}Para combinar seletores de label, usamos operadores de correspondência (matchers) como =, !=, =~ (regex correspondente) e !~ (regex negativa). Esses operadores servem para comparar valores de labels (ou aplicar expressões regulares) ao selecionar as séries desejadas. Veja alguns exemplos:
- Selecionar todas as métricas cujo nome começa com “http”:
{__name__=~"http.*"}Aqui, usamos o label especial __name__ (que representa o nome da métrica) com uma expressão regular para corresponder qualquer métrica cujo nome comece com “http”.
- Selecionar séries que possuem o label
statuscom valor exatamente “error”:
{status="error"}- Selecionar séries que possuem o label
appcom valor “frontend” ou “backend”:
{app=~"frontend|backend"}Nesse caso, o operador regex =~ com o padrão frontend|backend faz o seletor pegar séries cujo label app seja “frontend” ou “backend”.
Ao usar expressões regulares em seletores, é importante ter cuidado para não selecionar séries indesejadas. Por exemplo, um seletor como {job=~"prom.*"} traria todas as séries cujos labels job começam com “prom” — isso poderia incluir séries que não eram o alvo pretendido (como um job auxiliar relacionado).
Portanto, sempre procure ser o mais específico possível nos seletores para evitar correspondências acidentais.
Tipos de expressões em PromQL
PromQL oferece vários tipos de expressões para manipular as séries temporais coletadas pelo Prometheus. As principais incluem:
- Expressões aritméticas: Realizam cálculos matemáticos entre séries de métricas ou entre séries e constantes. Por exemplo, podemos somar duas métricas (
metric_a + metric_b), subtrair (metric_a - metric_b), multiplicar (metric_a * 100para converter em porcentagem), etc. Exemplo:
node_cpu_seconds_total{mode="system"} / node_cpu_seconds_total{mode="idle"} * 100Aqui calculamos a porcentagem de tempo que a CPU está no modo "system" em relação ao tempo no modo "idle".
- Funções de agregação: Agrupam e resumem séries temporais. As funções incluem
sum(soma),avg(média),max(máximo),min(mínimo),count(contagem), entre outras. Por exemplo:
sum(rate(http_requests_total[5m])) by (job)Nesta consulta, calculamos a taxa de requisições HTTP nos últimos 5 minutos (rate(http_requests_total[5m])) e em seguida somamos por job, ou seja, obtemos a taxa total por job.
- Funções de filtro: Filtram séries temporais com base em valores ou labels. Por exemplo, a função
topk(5, metric)retorna as 5 séries com os maiores valores para a métrica especificada. Exemplo:
topk(5, http_requests_total)Isso retornará as 5 séries de http_requests_total com os maiores valores.
-
Funções de transformação: Transformam séries temporais de maneiras específicas. Exemplos incluem:
rate(): calcula a taxa de aumento por segundo de um contador (derivada primeira) em uma janela de tempo.irate(): similar aorate(), mas calcula a taxa instantânea entre os dois pontos de dados mais recentes.increase(): calcula o total acumulado que o contador aumentou durante o período.delta(): calcula a diferença absoluta entre o primeiro e o último valor em uma janela de tempo.histogram_quantile(): calcula um quantil (por exemplo, 0.95 para 95º percentil) a partir de um histograma.
Exemplo de transformação com
histogram_quantile:histogram_quantile(0.95, rate(http_request_duration_seconds_bucket[5m]))Acima, estamos calculando o 95º percentil da distribuição de duração de requisições HTTP nos últimos 5 minutos, usando as séries
_bucketdo histograma de duração. -
Expressões booleanas (comparações): Avaliam condições verdadeiras ou falsas sobre os valores de séries temporais. Os operadores de comparação incluem
==(igual),!=(diferente),>(maior que),<(menor que),>=(maior ou igual) e<=(menor ou igual). Por padrão, ao comparar duas séries, o resultado é uma série booleana (1 para true, 0 para false) apenas para as combinações de séries que correspondem exatamente nos labels (veremos mais sobre correspondência de vetores adiante). Também é possível usar o modificadorboolpara forçar o resultado booleano a ser retornado.Um exemplo de expressão booleana combinada com cálculo:
rate(http_requests_total{status_code=~"5.."}[1m])
> rate(http_requests_total{status_code=~"2.."}[1m]) * 0.1Esta consulta verifica se a taxa de requisições HTTP com códigos de status 5xx no último minuto é maior que 10% da taxa de requisições 2xx no mesmo período. O resultado será uma série temporal booleana indicando, para cada combinação de labels, se a condição é verdadeira (1) ou falsa (0). Essa abordagem é útil em alertas.
Vector vs. Range Vector
Em PromQL, existem dois tipos principais de vetor que podem ser retornados em consultas: Instant Vector (vetor instantâneo) e Range Vector (vetor de intervalo).
-
Instant Vector (Vetor Instantâneo): Representa um conjunto de amostras (valor + timestamp) de múltiplas séries temporais, todas no mesmo instante no tempo. Cada série temporal no resultado possui os mesmos labels originais e um único valor correspondente ao momento da avaliação. Por exemplo, a expressão
cpu_usage{instance="webserver-1"}retornaria, no momento atual, o valor mais recente da métricacpu_usagepara a instânciawebserver-1. -
Range Vector (Vetor de Intervalo): Representa um conjunto de séries temporais, onde cada série contém um conjunto de amostras dentro de um intervalo de tempo especificado. Em vez de um único valor, cada série traz todos os pontos (timestamp, valor) coletados naquele intervalo. Range vectors são obtidos usando a sintaxe
[<duração>]após um seletor de métrica. Por exemplo,cpu_usage{instance="webserver-1"}[5m]retorna os últimos 5 minutos de dados da métricacpu_usagepara a instânciawebserver-1. As funções comorate(),increase()eavg_over_time()tipicamente esperam um range vector como entrada.
Exemplos de uso de Instant e Range vectors:
- Selecionando o valor atual (instantâneo) da métrica
cpu_usagepara a instância"webserver-1":
cpu_usage{instance="webserver-1"}- Calculando a diferença instantânea entre duas métricas (Instant Vector resultante):
http_requests_total - http_requests_failedAcima, subtraímos, para cada combinação de labels correspondente, o valor atual de http_requests_failed do valor atual de http_requests_total.
- Selecionando uma janela de 5 minutos de dados da métrica
cpu_usagepara cada instância (Range Vector):
cpu_usage[5m]- Calculando a taxa (por segundo) de
cpu_usagenos últimos 5 minutos para cada instância (note querate()retorna um Instant Vector, com a taxa calculada para cada série):
rate(cpu_usage[5m])- Obtendo o valor máximo da métrica
network_trafficem um intervalo de 30 minutos, separado por instância:
max_over_time(network_traffic[30m]) by (instance)Resumindo: um Instant Vector é adequado para consultas que requerem o valor atual (ou de um instante específico) de uma métrica, enquanto um Range Vector é necessário para consultas que envolvem cálculo ao longo do tempo (taxas, médias móveis, etc.). Muitas funções do PromQL, como
rateeavg_over_time, só funcionam com range vectors porque precisam de vários pontos de dados para produzir um resultado.
Segurança do seletor (Seletores seguros vs inseguros)
Ao escrever consultas PromQL, é importante construir seletores de métricas que capturem exatamente as séries desejadas, evitando resultados imprecisos ou indesejados. Alguns seletores podem ser considerados “inseguros” porque podem abranger séries não pretendidas.
Por exemplo, usar uma correspondência de prefixo muito genérica em um label pode ser problemático. Considere o seletor de label job=~"prom.*". Ele selecionará todas as séries de métricas cujo label job começa com “prom”.
Isso pode incluir não apenas o job principal “prometheus”, mas também qualquer outro job cujo nome comece com essas letras (por exemplo, um serviço “promtail” ou “prometheus-exporter”). O resultado pode ser uma consulta retornando séries inesperadas.
Para garantir seletores “seguros”, siga algumas práticas:
- Seja explícito nos valores de label: Prefira usar correspondência exata (
=ou!=) ou regex precisas. Por exemplo, se você quer métricas do job Prometheus, usejob="prometheus"em vez de um regex genérico. - Evite padrões muito abrangentes: Como regra, só use regex se realmente precisar capturar múltiplos valores similares. Mesmo assim, tente restringir o padrão. Regex tendem a ser menos eficientes, pois precisam testar o padrão contra todos os valores conhecidos de um label, e podem indicar que talvez a configuração dos labels deva ser melhorada.
- Conheça seus labels: Entenda quais labels cada métrica possui e quais valores são possíveis. Isso ajuda a criar seletores que não tragam surpresas.
Exemplos comparando seletores seguros vs inseguros:
- Seguro:
http_requests_total{job="webserver", status="error"}– seleciona exatamente as séries de requisições HTTP do serviçowebserverque possuem o status “error”. - Inseguro:
http_requests_total{status=~"err.*"}– poderia acidentalmente pegar algo como “erroneous” ou “errata” se esses fossem valores de status, além de “error”. Prefirastatus="error"se é esse o valor exato desejado. - Seguro:
{__name__=~"^http_.*_total$"}– seleciona métricas cujo nome começa com “http_” e termina com “_total”. - Inseguro:
{__name__=~"http"}(sem âncoras ou wildcards definidos) – esse seletor está incompleto e potencialmente inválido. Sempre especifique padrões completos, por exemplohttp.*se a intenção é “começa com http”.
Em suma, construa seletores de forma cuidadosa para evitar incluir séries indesejadas. Isso garante que suas consultas retornem dados precisos e também evita sobrecarregar o Prometheus com resultados excessivos.
Obsolescência do vetor instantâneo (Staleness)
Um detalhe importante ao usar vetores instantâneos: o Prometheus possui um mecanismo de staleness (obsolescência) para lidar com séries temporais que não receberam novos dados em um intervalo de tempo.
Por padrão, se uma métrica não tiver amostras recentes (normalmente nos últimos 5 minutos), o PromQL considerará essa série como ausente ou retornará um valor NaN (not a number) em vez de continuar mostrando um valor antigo. Isso evita apresentar dados “velhos” como se fossem atuais.
Porém, em algumas consultas, especialmente ao criar alertas, queremos detectar explicitamente quando uma métrica parou de ser enviada. Existem maneiras de lidar com isso:
- Aumentar a janela de consulta: Em vez de consultar apenas o valor instantâneo, podemos consultar em uma janela de tempo para ver se há dados recentes. Por exemplo, usar uma subconsulta com intervalo:
http_requests_total[5m]garante que estamos inspecionando 5 minutos de dados. Ou então, usar funções como max_over_time(metric[5m]) para pegar o último valor nos últimos 5 minutos.
- Usar funções de ausência: O PromQL oferece a função
absent()que retorna 1 se a expressão dentro dela não retornar nenhum dado. Por exemplo:
absent(rate(http_requests_total[5m]))retornará 1 (com um label indicando a série buscada) se nenhuma série http_requests_total tiver dados nos últimos 5 minutos – ou seja, indicando que possivelmente a coleta parou. Caso exista qualquer dado, absent() retorna uma série vazia.
Também há a variante absent_over_time(metric[duração]), que verifica se no intervalo dado a métrica esteve ausente o tempo todo.
- Combinar com condições booleanas: Podemos filtrar séries pelo timestamp de sua última amostra. A função
timestamp(metric)retorna o timestamp da última amostra daquela métrica. Assim, expressões como:
timestamp(cpu_usage) < time() - 30identificam séries cujo último timestamp é inferior a 30 segundos atrás, ou seja, possivelmente desatualizadas.
Exemplos práticos:
- Verificar métricas ausentes:
http_requests_total unless absent(rate(http_requests_total[5m]))Aqui, usamos unless (que retorna a série da esquerda exceto quando a da direita existe) para só manter http_requests_total se ela não estiver ausente nos últimos 5m. Isso efetivamente filtra fora séries que não receberam dados recentes.
- Filtrar instâncias inativas (não reportando):
cpu_usage unless absent_over_time(cpu_usage[2m])Essa consulta retornaria cpu_usage atual apenas para instâncias que tiveram dados nos últimos 2 minutos. Se alguma instância parou de reportar (logo, ausente nos últimos 2m), ela será excluída do resultado.
- Combinar timestamp e booleano:
cpu_usage * on(instance) group_left() ((time() - timestamp(cpu_usage)) < 30)Esta expressão resulta no valor de cpu_usage apenas para instâncias cujo último timestamp tem menos de 30 segundos de idade. Estamos multiplicando o valor atual de cpu_usage por uma condição booleana que vale 1 apenas para instâncias atualizadas recentemente (e 0 para instâncias atrasadas).
O uso de * on(instance) group_left() garante que combinamos corretamente cada instância com sua condição booleana.
Em resumo, devido ao comportamento de staleness, um vetor instantâneo pode não mostrar valores de métricas atrasadas. Para contornar isso, podemos usar janelas de tempo maiores ou funções especiais como absent() para tratar casos de ausência de dados.
Funções Matemáticas e Clamping
As funções em PromQL permitem manipular e processar métricas de diversas formas. Dentre as mais comuns estão as funções matemáticas, que realizam operações aritméticas sobre as séries de métricas. Temos desde as operações básicas até funções matemáticas de biblioteca. Alguns exemplos:
sqrt(vector): retorna a raiz quadrada de cada valor no vetor.exp(vector): retorna o exponencial (e^x) de cada valor.ln(vector): logaritmo natural.log10(vector),log2(vector): logaritmos base 10 e base 2, respectivamente.ceil(vector),floor(vector): arredondamento para cima ou baixo.
Além disso, PromQL fornece funções para limitar valores extremos (clamping). As funções clamp_min(vector, scalar) e clamp_max(vector, scalar) limitam os valores de um vetor a um mínimo ou máximo especificado. Por exemplo:
clamp_min(metric, 0): garante que nenhum valor da sériemetricseja menor que 0 (valores negativos seriam substituídos por 0).clamp_max(usage_ratio, 1): garante que valores acima de 1 emusage_ratio(por exemplo, 100% de uso) sejam reduzidos para 1.
Essas funções de clamping são úteis para evitar que ruídos ou anomalias atrapalhem visualizações. Por exemplo, se um cálculo produz temporariamente um valor negativo ou um valor absurdamente alto por conta de algum atraso ou jitter, podemos usar clamping para limitar a escala dos gráficos.
Exemplos de uso de funções matemáticas e clamping:
- Calcular a média dos valores de uma métrica nos últimos 5 minutos:
avg_over_time(metric_name[5m])- Calcular a soma dos valores de uma métrica nos últimos 10 minutos:
sum_over_time(metric_name[10m])- Calcular o máximo valor de uma métrica nos últimos 1 hora, filtrando por um label:
max_over_time(metric_name{label="value"}[1h])- Limitar o valor de uma métrica entre 0 e 100:
clamp_min(clamp_max(metric_name, 100), 0)(Aplica clamp_max para limitar a 100 e depois clamp_min para garantir mínimo 0.)
- Converter uma fração em porcentagem e garantir que não passe de 100%:
clamp_max(success_ratio * 100, 100)Supondo que success_ratio seja uma métrica ou expressão que resulta em um valor entre 0 e 1 (por exemplo, proporção de sucesso), multiplicamos por 100 para obter porcentagem e usamos clamp_max para nunca exibir acima de 100%.
Conhecer e utilizar essas funções permite realizar consultas mais avançadas e obter insights mais precisos a partir dos dados coletados.
Timestamps e Funções de Tempo e Data
No PromQL, timestamps (carimbos de tempo) são representados internamente como números de ponto flutuante indicando segundos desde a época Unix (1º de janeiro de 1970, 00:00:00 UTC).
Embora normalmente não precisemos lidar diretamente com o valor numérico do timestamp, há funções úteis relacionadas ao tempo:
-
time(): retorna o timestamp Unix do momento atual (momento da avaliação da consulta). Pode ser utilizado, por exemplo, para calcular diferenças de tempo. Exemplo:time() - 3600produziria um valor de timestamp correspondente a uma hora atrás. -
timestamp(vetor): retorna, para cada série no vetor dado, o timestamp da última amostra daquela série. Útil para comparações e detecção de desatualização (como visto anteriormente).
Além disso, existem funções para extrair componentes de data/hora do timestamp de cada amostra de uma série:
day_of_week(vetor): retorna o dia da semana (0–6, onde 0 = domingo, 1 = segunda, etc.) de cada amostra no vetor dado.hour(vetor): retorna a hora (0–23) do timestamp de cada amostra.day(vetor),month(vetor),year(vetor): retornam respectivamente o dia do mês, o mês (1–12) e o ano do timestamp de cada amostra.
Essas funções permitem criar consultas que dependem da hora ou dia. Por exemplo, você pode querer detectar padrões diurnos ou disparar alertas apenas em dias úteis.
Exemplos de uso de funções de tempo e data:
- Obter o timestamp atual (como escalar):
time()- Extrair a hora atual do dia como um valor (0–23):
hour(vector( time() ))Aqui, vector(time()) converte o escalar retornado por time() em um vetor (necessário porque hour() espera um vetor). O resultado é um vetor com um único valor: a hora do dia.
- Calcular a média de uma métrica por hora do dia, nos últimos 24h (usando subconsulta para separar por hora):
avg_over_time(my_metric[1h])[24h:1h]Essa expressão é uma subconsulta que calcula avg_over_time(my_metric[1h]) (média de my_metric em cada janela de 1h) para cada hora nas últimas 24 horas. Isso produz uma série de 24 pontos, um para cada hora, que pode ser útil para observar a variação horária.
- Selecionar o valor médio da métrica
my_metricno último dia:
avg_over_time(my_metric[1d])(Assumindo que há dados suficientes para cobrir o último dia inteiro.)
- Nota: Para consultar um período específico (entre timestamps específicos), não há uma sintaxe direta dentro do PromQL. Em vez disso, usa-se a API de consulta de intervalos do Prometheus (fornecendo
starteendno request) ou ferramentas como Grafana para delimitar visualmente o período. Dentro do PromQL, operações de tempo são relativas (como “últimos 5 minutos”, “últimas 24h”, etc.) em relação ao momento de avaliação.
Counter Range Vectors, Agregação Temporal e Subconsultas
Counter Range Vectors: Contadores são métricas que apenas aumentam (ou resetam para zero e voltam a aumentar). Exemplos: número total de requisições atendidas, bytes transferidos, etc. Quando consultamos diretamente um counter como range vector, obteremos uma série de pontos que só crescem (com eventuais resets). Para extrair informações úteis (como taxa de eventos por segundo ou aumentos em determinado período) usamos funções especiais:
rate(counter[5m]): Calcula a taxa média por segundo de incremento do contador nos últimos 5 minutos. Essa função já lida corretamente com resets do contador (ignorando as quedas abruptas devido a resets e calculando a taxa considerando isso).irate(counter[5m]): Calcula a taxa instantânea (baseada apenas nos dois pontos mais recentes dentro dos 5 minutos). É mais ruidosa, mas pode reagir mais rapidamente a mudanças repentinas.increase(counter[1h]): Calcula quanto o contador aumentou no último 1 hora. Essencialmente integra a taxa ao longo do período.
Agregação através do tempo (Aggregating Across Time): Às vezes, queremos primeiro agregar os dados e depois analisar a evolução temporal dessa agregação. As subconsultas nos permitem isso. Uma subquery (subconsulta) é quando temos uma expressão do PromQL seguida de um intervalo entre colchetes e possivelmente uma resolução, por exemplo: expr[duração:passo]. Isso faz o Prometheus avaliar expr repetidamente ao longo do intervalo dado, produzindo um range vector como resultado.
Por exemplo, avg_over_time(rate(http_requests_total[1m])[24h:1h]) funciona assim:
- Internamente,
rate(http_requests_total[1m])é avaliado para cada passo de 1h dentro das últimas 24h, gerando a taxa média por minuto calculada a cada hora. - Em seguida,
avg_over_time(...[24h:1h])calcula a média desses 24 valores (um por hora) no tempo atual. Na prática, isso nos daria a média da taxa horária de requisições no dia.
Subconsultas são muito poderosas e foram aprimoradas a partir do Prometheus 2.7. Com elas é possível, por exemplo, calcular tendências, baselines e sazonalidade de forma compacta.
Exemplos avançados de subconsultas e análise de tendências:
- Tendência de taxa de erro (janela móvel): Calcular a média da taxa de erros em janelas de 1 hora, ao longo das últimas 24 horas:
avg_over_time(
rate(http_requests_total{status=~"5.."}[1m])[24h:1h]
)Essa consulta gera 24 pontos (taxa de erro média de cada hora nas últimas 24h) e depois calcula a média disso tudo (ou seja, a média diária da taxa de erro). Poderíamos também omitir a função externa para simplesmente visualizar a série das últimas 24 horas e identificar padrões de aumento ou redução de erros ao longo do dia.
- Baseline de performance (comparação com média histórica): Comparar a performance atual com a média da última semana:
rate(http_requests_total[5m])
/ avg_over_time(rate(http_requests_total[5m])[7d])Essa consulta produz uma razão: valores acima de 1 indicam que a taxa atual de requisições está acima da média semanal; valores abaixo de 1, abaixo da média. Isso pode ser útil para identificar desvios significativos de tráfego.
- Detecção de anomalia sazonal (padrão horário): Comparar o tráfego atual com o padrão do último dia:
rate(http_requests_total[5m])
/ avg_over_time(rate(http_requests_total[5m])[24h:1h])Aqui, o denominador avg_over_time(...[24h:1h]) produz a média da taxa em cada hora do dia anterior. Dividindo a taxa atual por esse valor da mesma hora ontem, podemos identificar se o tráfego está anormalmente alto ou baixo para este horário do dia.
- Diferença diária (subconsulta com offset): Para calcular a diferença em uma métrica entre hoje e ontem, podemos usar
offset. Exemplo:
my_metric - my_metric offset 1dIsso resulta em quanto my_metric variou em comparação com exatamente 24 horas atrás.
- Soma acumulada (exemplo de subconsulta):
sum(my_counter) - sum(my_counter) offset 1dEste exemplo soma o contador my_counter (provavelmente de várias instâncias) e subtrai o valor de 1 dia atrás, mostrando o incremento total em um dia. Essa é outra forma de calcular algo similar a increase(my_counter[1d]).
Em todos esses casos, as subconsultas [ ... ] estão permitindo observar ou reutilizar resultados ao longo do tempo dentro de uma única expressão.
Histogramas, Mudança de Tipo, Alteração de Labels e Ordenação
Histogramas: Em Prometheus, histogramas são uma forma de metricar distribuições de valores (duração de requisições, tamanho de payloads, etc.). Um histograma clássico consiste em múltiplas séries: por convenção, se a métrica base é request_duration_seconds, as séries serão:
request_duration_seconds_bucket{le="0.1", ...}(um bucket contando quantas observações <= 0.1s)- vários outros buckets com diferentes limites
le(le = limite inferior ou igual) request_duration_seconds_count(contagem total de observações)request_duration_seconds_sum(soma total dos valores observados)
Para analisar histogramas, geralmente somamos as séries _bucket por limite para agregar todas as instâncias ou rótulos de interesse. É crucial incluir o label le ao agregar buckets. Por exemplo, a forma correta de agregar um histograma de duração por job seria:
sum by (job, le) (rate(http_request_duration_seconds_bucket[5m]))Depois de agregado adequadamente, podemos aplicar histogram_quantile() para extrair quantis (p50, p90, p99, etc.).
Trabalhando corretamente com histogramas:
- Exemplo canônico (p99 de latência HTTP):
histogram_quantile(
0.99,
sum(rate(http_request_duration_seconds_bucket[5m])) by (le)
)Esse retorna o 99º percentil da duração das requisições HTTP considerando todos os buckets. Note o uso de by (le) dentro do sum.
- Agregando por labels extras: Se quisermos o percentil por
jobeinstance, por exemplo, devemos manter esses labels na agregação, além dole:
histogram_quantile(
0.95,
sum(rate(http_request_duration_seconds_bucket[5m])) by (job, instance, le)
)-
Evitando erro comum: Nunca esqueça o
by (le)ao somar buckets de um histograma clássico. Por exemplo, isto está errado:# Exemplo INCORRETO - ausência de by(le) histogram_quantile(0.95, sum(rate(http_request_duration_seconds_bucket[5m])))
Sem agrupar por le, os valores de buckets se somam indevidamente, tornando o resultado do quantil incorreto.
No Prometheus 3.0, foram introduzidos os histogramas nativos (ainda experimentais). Eles visam simplificar e tornar mais eficiente o uso de histogramas (evitando lidar com dezenas de séries _bucket).
Com histogramas nativos, existem inclusive novas funções como histogram_count(), histogram_sum() e histogram_avg() para extrair diretamente contagem, soma e média dos histogramas.
Além disso, há a função histogram_fraction() para calcular frações entre limites. Embora seja um recurso promissor, a maioria dos usuários ainda trabalha com histogramas clássicos _bucket até que os nativos se estabilizem.
Mudança de tipo (conversão Escalar <-> Vetor): Em algumas situações avançadas, você pode precisar converter escalares em vetores ou vice-versa:
scalar(vetor)– Converte um vetor de uma única série temporal (com um único valor) em um escalar simples. Isso é útil, por exemplo, quando você calculou um valor mínimo ou máximo e quer usá-lo em uma comparação global. Exemplo:scalar(min(up{job="webserver"}))– isso resultará em um escalar 0 ou 1 indicando se alguma instância do job “webserver” está caída (0 se o mínimo for 0, ou seja, pelo menos uma instância está down; 1 se todas estão up).vector(escalar)– O oposto, pega um escalar e o transforma em um vetor (sem labels). Útil se você precisa combinar um número puro com séries. Exemplo:vector(1)– produziria um vetor contendo apenas o valor 1.
Alteração de Labels: Às vezes é necessário renomear ou copiar labels nas séries. Funções úteis:
label_replace(vetor, "label_destino", "valor_novo", "label_origem", "regex")– Retorna um vetor a partir de outro, adicionando ou modificando um label. Ele pega o valor dolabel_origemque case com a regex fornecida e o coloca emlabel_destinousandovalor_novo(onde'$1'pode referenciar grupos da regex). Exemplo:
label_replace(my_metric, "new_label", "$1", "old_label", "(.*)")Isso criaria (ou sobrescreveria) new_label em cada série de my_metric, copiando exatamente o valor de old_label (já que (.*) captura todo o valor e $1 insere ele).
label_join(vetor, "label_destino", "sep", "label1", "label2", ...)– Concatena múltiplos labels em um só. Ex:label_join(my_metric, "instance_job", "-", "instance", "job")criaria um novo labelinstance_jobjuntando os valores deinstanceejobseparados por um-.
Essas funções não são usadas com frequência em consultas ad-hoc, mas podem ser muito úteis ao preparar métricas para certas comparações ou ao lidar com diferenças de rotulagem entre métricas.
Ordenação (Sorting): Para ordenar resultados, podemos usar as funções sort(vector) (ordem crescente) e sort_desc(vector) (ordem decrescente). Isso pode ser útil quando estamos interessados no topo ou no final de uma lista de resultados (embora muitas vezes topk e bottomk já cubram esses casos).
Exemplos rápidos:
-
Ordenar todas as instâncias pelo uso de CPU decrescente:
sort_desc(rate(node_cpu_seconds_total{mode!="idle"}[5m])) by (instance))(Aqui somamos as CPUs por instância implicitamente ao usar o
by (instance)na expressão, e depois ordenamos.) -
Ordenar alfabéticamente por valor de um label (pouco comum, mas possível):
sort(my_metric)(Se
my_metricé um escalar ou tem apenas um valor por série,sort()essencialmente ordenará pelos labels já que os valores podem ser iguais.)
Valores ausentes (Absent / Missing Values)
Valores ausentes podem ocorrer quando uma métrica não é reportada (por exemplo, um serviço caiu ou foi desligado). Em consultas PromQL, um valor ausente simplesmente não aparece no resultado. Entretanto, podemos detectar explicitamente a ausência de séries usando a função absent() mencionada anteriormente.
Recapitulando o uso de absent():
absent(metric)– Retorna uma série sem labels (ou com labels especificados na consulta) com valor 1 se nenhuma série correspondente ametricestá presente, ou retorna nada (vazio) caso contrário. Isso é muito útil em regras de alerta: um alerta de “TargetDown” pode ser escrito comoabsent(up{job="myjob"} == 1)para disparar quando nenhum alvo daquele job estiver up.
Exemplo:
absent(up{job="node"} == 1)Acima, a expressão up{job="node"} == 1 resultaria em 1 para cada instância de node que esteja up, então absent(...) retornaria 1 (sem label) se nenhuma instância de node estiver up (ou seja, o resultado dentro foi vazio). Se pelo menos uma instância estiver up, absent não retorna nada.
Da mesma forma, absent_over_time(metric[5m]) verifica se nenhum ponto de metric apareceu nos últimos 5 minutos.
Importante: Ao visualizar dados no gráfico do Prometheus ou Grafana, séries ausentes simplesmente não aparecem. Por isso, ao compor dashboards ou alertas, pode ser útil usar consultas que retornem 0 explicitamente quando algo está ausente para facilitar a visualização. Uma técnica é usar a operação OR com absent(). Exemplo:
rate(http_requests_total[5m]) or absent(http_requests_total)Isso retornará a taxa de requisições normalmente; se nenhuma série existir, em vez de nada, retornará 1 (ou outro valor constante) indicando ausência.
Funções avançadas e menos conhecidas
Algumas funções do PromQL são menos conhecidas, mas podem ser extremamente poderosas em cenários específicos:
-
resets(counter[interval]): Conta quantas vezes um contador “resetou” (voltou a zero) no período. Útil para detectar reinicializações de aplicativos ou problemas de coleta. Exemplos:resets(http_requests_total[5m])Contaria quantos resets ocorreram no
http_requests_totalnos últimos 5 minutos. Se esse número for > 0 constantemente, pode indicar que o serviço está reiniciando frequentemente (se o contador for interno ao serviço) ou que há overflow de contadores. -
changes(series[interval]): Conta quantas vezes o valor de uma série mudou durante o intervalo. Isso vale para qualquer métrica (não apenas counters). Pode indicar instabilidade ou flapping. Exemplo:changes(process_start_time_seconds[5m]) > 0O exemplo acima retornaria 1 para instâncias cujo
process_start_time_seconds(normalmente um timestamp de início do processo) tenha mudado nos últimos 5 minutos — ou seja, o processo reiniciou nesse período. -
predict_linear(series[interval], passos_no_futuro): Realiza uma extrapolação linear do valor da série com base na tendência nos últimos intervalos e prevê o valor daqui a X segundos (informado empassos_no_futuro). Útil para prever quando algo alcançará um certo limite. Exemplo:predict_linear(node_filesystem_free_bytes[1h], 3600) < 0Poderia ser usado para alertar se a tendência de queda do espaço livre prevê que em 1 hora (
3600segundos) o espaço chegaria a zero. -
holt_winters(series[interval], sf, tf): Embora mais comum no Graphite, o PromQL também tem uma função de previsão chamadaholt_winters(Holt-Winters, série temporal com tendência e sazonalidade). Aceita uma série (geralmente resultado de subconsulta) e realiza suavização exponencial dupla. No entanto, essa função é raramente usada diretamente em alertas, servindo mais para visualização de tendências suavizadas. -
Funções para histogramas nativos (Prometheus 3.x):
histogram_count()ehistogram_sum()– Retornam, respectivamente, a contagem total e a soma total das observações de histogramas (clássicos ou nativos). Para histogramas clássicos, esses usam as séries_counte_suminternas; para nativos, usam os valores codificados.histogram_avg()– Computa a média dos valores observados em cada histograma, equivalente ahistogram_sum/histogram_count.histogram_fraction(lower, upper, hist)– Estima a fração de observações dentro do intervalo[lower, upper]para cada histograma. Útil, por exemplo, para calcular Apdex (fração de requisições abaixo de um certo limiar de latência).
Lembrando que algumas dessas funções mais novas podem requerer flags experimentais, dependendo da versão do Prometheus.
Operadores Aritméticos e Correspondência de Vetores Simples
PromQL permite usar operadores binários entre séries temporais para calcular novas séries. Os operadores aritméticos são: +, -, *, /, % (módulo) e ^ (exponenciação). Eles podem operar entre:
- Escalar e escalar (ex.:
2 * 3) - Vetor e escalar (o escalar aplica-se a todos os valores do vetor; ex.:
metric * 100) - Vetor e vetor (aqui entra o conceito de correspondência de vetores)
Quando aplicamos um operador entre dois vetores (Instant Vectors), o PromQL realiza a operação par a par entre séries que “correspondem” umas às outras. Essa correspondência por padrão requer que as séries tenham exatamente os mesmos labels (nome da métrica pode ser diferente, mas os rótulos-chave e seus valores devem coincidir).
Exemplo simples: se temos as séries metric_a{host="A", env="prod"} com valor X e metric_b{host="A", env="prod"} com valor Y, então metric_a + metric_b retornará {host="A", env="prod"} com valor X+Y. Se não houver correspondência exata de labels entre alguma série de metric_a e alguma de metric_b, aquela combinação não aparece no resultado.
Correspondência simples: Por padrão, todos os labels (exceto o nome da métrica) devem casar entre as duas séries para a operação acontecer. É possível ajustar isso com modificadores que veremos adiante (on e ignoring).
Se quisermos forçar a operação em todas as combinações (o que raramente faz sentido), há o modificador cross_join (PromQL >2.9), mas geralmente ele não é utilizado porque o comportamento padrão já é suficiente.
Os operadores também podem ser usados com o modificador bool, mas isso só se aplica a operadores de comparação, não aos aritméticos.
Exemplos práticos de operadores aritméticos:
-
Soma de métricas:
http_requests_total{status="200"} + http_requests_total{status="500"}Aqui, somamos as séries de requisições com status 200 e as com status 500, casando por quaisquer outros labels (por exemplo, instância). O resultado é o total combinado de requisições de sucesso e erro.
-
Diferença de métricas:
node_memory_MemTotal_bytes - node_memory_MemFree_bytesCalcula a memória em uso (diferença entre total e livre) para cada instância, assumindo que ambas as métricas compartilham os labels de instância.
-
Multiplicação por escalar:
cpu_usage * 100Converte a métrica
cpu_usage(talvez como fração 0–1) em porcentagem. -
Combinação de dois vetores diferentes:
errors_total / requests_totalPode calcular a taxa de erro (assumindo que
errors_totalerequests_totalcompartilham labels como serviço/endpoint). Isso exige correspondência exata de labels.
No caso acima, se errors_total existir para um determinado label e requests_total não, essa combinação não retorna resultado. Podemos usar vector matching avançado (próxima seção) para ajustar essas situações.
Correspondência de Séries Temporais: on(), ignoring(), group_left, group_right
Quando combinamos métricas diferentes (vetor-vetor), muitas vezes precisamos controlar quais labels são usados para fazer o join (união) entre as séries de cada lado da operação. É aqui que entram os modificadores on e ignoring, e os operadores de junção externa group_left e group_right:
-
on(lista_de_labels): Especifica explicitamente quais labels devem ser usados para casar as séries ao aplicar o operador. Todos os demais labels são ignorados no matching (exceto os doonlistados). Exemplo:errors_total / on(instance) requests_totalAqui dizemos: combine séries de
errors_totalerequests_totalque tenham o mesmo valor deinstance. Labels diferentes deinstanceserão ignorados na comparação. Isso é útil se, por exemplo,errors_totaltem um labelstatus="5xx"enquantorequests_totalnão tem o labelstatus. Sem oon(instance), essas séries não casariam por terem conjuntos de labels distintos. -
ignoring(lista_de_labels): O inverso doon. Use todos os labels exceto os listados para fazer o matching. Ou seja, finge que os labels mencionados não existem nos vetores ao procurar pares correspondentes. Exemplo:cpu_usage{cpu="total"} / ignoring(cpu) cpu_quotaSuponha que
cpu_usagetenha um labelcpu(núcleo) e valor"total"para indicar uso total da CPU, enquantocpu_quotanão tem esse label (aplica a todo CPU). Oignoring(cpu)permite desconsiderar essa diferença, casando as séries somente pelos outros labels (por exemplo, pod ou contêiner, se for o caso). -
Junções um-para-muitos (many-to-one): Por padrão, se houver múltiplas séries de um lado que poderiam casar com uma série do outro, a operação não ocorre e o resultado é vazio para evitar ambiguidades. No entanto, às vezes desejamos permitir isso — por exemplo, dividir uma métrica total por número de CPUs, onde a métrica total não tem o label
cpumas a de contagem de CPU tem (múltiplas séries, uma por core). Para isso, usamosgroup_leftougroup_rightem conjunto comon/ignoring:group_left(label1, label2, ...): Indica que as séries do lado esquerdo do operador devem permanecer separadas (muitas) enquanto as do lado direito serão “espalhadas” para casar. Em outras palavras, permite que uma única série do lado direito seja usada para múltiplas do lado esquerdo. Opcionalmente, podemos listar labels que serão copiados do lado direito para o resultado final.group_right(label1, label2, ...): O contrário, mantém o lado direito com muitas séries e espalha o lado esquerdo.
Exemplo (adicionando labels com group_left):
rate(http_requests_total[5m]) * on(instance) group_left(job, environment) upNesse exemplo,
rate(http_requests_total[5m])produz séries talvez com labelsinstancee outros, mas digamos que não tenhajobnemenvironmentexplicitamente (ou queremos copiar doup). A sérieup(métrica de saúde do alvo) temjob,instance, eenvironment. Estamos multiplicando as duas métricas apenas casando porinstance(on(instance)). Como do lado direito (up) há possivelmente apenas uma série por instance (valor 0 ou 1), e do lado esquerdo pode haver múltiplas (por caminho de requisição, status, etc.), usamosgroup_left(job, environment)para dizer: permite que a mesma série deupcase com múltiplas séries de requests do lado esquerdo, e traga os labelsjobeenvironmentdessa série deuppara o resultado final. Assim, o resultado terá a taxa de requests porinstancemas agora enriquecido com os labels de job e environment.Exemplo (many-to-one sem copiar labels):
cpu_usage / on(instance) group_right cpu_countSuponha que
cpu_usage{instance="A"}representa o uso total de CPU (consolidado) em determinada máquina, ecpu_count{instance="A", cpu="0"}ecpu_count{instance="A", cpu="1"}etc. representam 1 para cada CPU física (cada core). Se somarmoscpu_count by (instance)obteríamos o número de CPUs por instância, mas podemos diretamente dividir usando o truque dogroup_right. Aqui, cada série decpu_usage(uma por instancia) será comparada com múltiplas séries decpu_count(uma por CPU). Semgroup_right, não casaria por haver múltiplas séries do lado direito para o mesmo instance. Comgroup_right, permitimos isso e, por não especificar labels a copiar, o resultado herda os labels do lado esquerdo (cpu_usage), e a operação divisão é feita para cada combinação (na prática repetindo o mesmo valor decpu_usagepara cada CPU e dividindo por o respectivocpu_count– o que acaba resultando no mesmo valor para cada CPU). Talvez nesse caso específico fosse melhor já agruparcpu_countantes de dividir, mas esse exemplo ilustra a sintaxe. -
Operador de conjunto
union: PromQL não possui um operador explícito “UNION” nomeado, mas podemos realizar união de resultados simplesmente listando expressões separadas por vírgula em uma consulta. Por exemplo:metric_a, metric_bIsso retorna todas as séries de
metric_ae todas as demetric_b. Não é muito comum em consultas manuais, mas pode ser útil para junção visual.
Resumindo, os modificadores on e ignoring controlam quais labels considerar ao casar séries de métricas diferentes, e group_left/group_right controlam como lidar quando há cardinalidades diferentes (um-para-muitos). Combiná-los corretamente é fundamental para escrever consultas que envolvam múltiplas métricas.
Operadores Lógicos: and, or, unless
Além dos operadores aritméticos e de comparação, PromQL também suporta operadores lógicos para vetores. Esses operadores não criam valores numéricos novos, mas sim filtram ou combinam séries com base em condições booleanas.
-
and: Retém apenas as séries que aparecem em ambos os operandos. Em outras palavras, é uma interseção: uma série do lado esquerdo só passa se existe uma série exatamente igual do lado direito (considerando labels) e vice-versa. O valor resultante de cada série será o valor do lado esquerdo (padrão) ou, se usado como comparador, segue regras de comparador bool. Uso típico: aplicar uma condição a um resultado. Por exemplo:(vector1 comparacao const) and vector1Isso retornaria apenas as séries de
vector1que atendem à comparação (pois o comparador produzirá 1 para as séries que satisfazem, e entãoandmanterá apenas essas). -
or: União de séries. Retorna séries que estão em pelo menos um dos lados. Se a mesma série (mesmos labels) aparece em ambos, o valor resultante será o do lado esquerdo (padrão) ou pode ser modificado com bool se estivermos combinando booleanos. É útil para combinar resultados diferentes. Por exemplo:vector_a or vector_bIsso dá todas as séries de
vector_aevector_b. Se alguma série estiver presente nos dois, aparece uma vez só (com valor devector_a). -
unless: Retém as séries do lado esquerdo a menos que elas também apareçam no lado direito. Equivale a diferença de conjuntos: resultado = esquerda \ direita. (Obs: O lado direito só importa pelos labels, seus valores são ignorados). Por exemplo:up{job="api"} unless up{job="api", region="us-east"}Isso retornaria as séries
updo job “api” que não têm region=“us-east”, ou seja, efetivamente filtra fora todas as instâncias da região us-east.
Os operadores lógicos são avaliados após todos os cálculos numéricos serem feitos. Isso significa que podemos usá-los tanto em métricas brutas quanto em resultados de expressões.
Exemplos práticos combinando comparações e operadores lógicos:
-
Contar instâncias ativas em dois grupos diferentes:
sum(up{job="node"} == 1) or sum(up{job="db"} == 1)Esse exemplo usa
== 1para converter as sériesupem booleanas (1 para up, 0 para down) e soma para contar quantas estão up em cada job. Ooraqui faz a união, retornando duas séries (uma para node e outra para db) com o valor de quantas instâncias estão up em cada. -
Filtrar top 5 de um conjunto e combinar com outro critério:
topk(5, rate(http_requests_total[5m])) and ignoring(instance) (rate(errors_total[5m]) > 0)Esse exemplo hipotético pegaria as 5 maiores taxas de requisição (independente de instância) e então, através do
andcomignoring(instance)e a condição de erros, manteria somente aquelas cujo serviço (ignorando instâncias) está apresentando erros. Bastante específico, mas demonstra o uso combinado:topkproduz séries; a outra parte produz 1/0 para serviços com erro; oand ignoring(instance)casa por serviço e filtra.
Lembrando que, se quisermos comparar valores de uma série com um número e obter diretamente 1 ou 0, podemos usar o modificador bool. Exemplo: vector1 > bool 10 retornaria um vetor com valor 1 para séries onde vector1 > 10 e 0 caso contrário (mantendo os labels). Sem bool, ele retornaria as próprias séries (com seus valores originais) porém filtradas pelas que atendem à condição.
Resumo de operadores de conjunto (conjuntos de séries)
Já falamos sobre on, ignoring, group_left, group_right e os operadores lógicos. Vale reforçar:
on/ignoring: controlam quais labels fazem parte da comparação entre séries ao aplicar um operador binário.group_left/group_right: permitem matching many-to-one e definem de que lado as séries duplicadas ficam.and,or,unless: operam em nível de conjunto de séries (interseção, união, diferença).
Além disso, quando usamos agregadores (como sum, avg etc.), usamos by ou without para controlar quais labels serão preservados ou removidos. Isso às vezes é referido como agrupar por labels, mas é diferente de on/ignoring (que é para matching de operadores).
Recapitulando agregação com by e without:
sum by(label1, label2) (expr)– Soma os valores deexpragrupando séries que compartilham os mesmos valores delabel1elabel2. Os labelslabel1elabel2serão mantidos no resultado, e todos os outros serão descartados (exceto aqueles usados no by).avg without(labelX) (expr)– Calcula a média removendolabelXda distinção. Isso significa agrupar por todas as outras labels, ou seja, fundir séries que diferem apenas emlabelX.
Exemplo: sum by(job) (up == 0) – contaria quantas instâncias estão down por job. Aqui up == 0 produz 1 para instâncias down. Agrupando por job e somando, obtemos a contagem de instâncias não ativas de cada job.
Funções Essenciais do PromQL
As funções essenciais do PromQL são aquelas mais utilizadas no dia a dia para monitoramento e análise de métricas. Elas permitem transformar dados brutos em informações acionáveis, calculando taxas, agregações e estatísticas importantes.
Funções de Taxa e Incremento
As funções mais fundamentais para trabalhar com contadores são rate() e increase():
rate(counter[interval]): Calcula a taxa média por segundo de incremento do contador no intervalo especificado. Esta função lida automaticamente com resets do contador.
rate(http_requests_total[5m])increase(counter[interval]): Calcula quanto o contador aumentou no intervalo especificado.
increase(http_requests_total[1h])irate(counter[interval]): Calcula a taxa instantânea baseada apenas nos dois pontos mais recentes. É mais ruidosa, mas reage mais rapidamente a mudanças.
irate(http_requests_total[5m])Funções de Agregação
As funções de agregação permitem resumir dados de múltiplas séries:
sum(expr) by (label1, label2): Soma os valores agrupando por labels específicos.
sum(rate(http_requests_total[5m])) by (job)avg(expr) by (label1, label2): Calcula a média agrupando por labels específicos.
avg(rate(node_cpu_seconds_total{mode="user"}[5m])) by (instance)count(expr) by (label1, label2): Conta o número de séries agrupando por labels.
count(up) by (job)max(expr) by (label1, label2): Retorna o valor máximo agrupando por labels.
max(rate(http_requests_total[5m])) by (endpoint)min(expr) by (label1, label2): Retorna o valor mínimo agrupando por labels.
min(rate(http_requests_total[5m])) by (endpoint)Funções de Percentil e Histograma
histogram_quantile(quantile, histogram): Calcula um quantil específico a partir de um histograma.
histogram_quantile(0.95, sum(rate(http_request_duration_seconds_bucket[5m])) by (le))quantile(quantile, expr): Calcula um quantil específico de uma expressão.
quantile(0.95, rate(http_requests_total[5m]))Funções de Filtro e Seleção
topk(k, expr): Retorna as k séries com os maiores valores.
topk(5, rate(http_requests_total[5m]))bottomk(k, expr): Retorna as k séries com os menores valores.
bottomk(5, rate(http_requests_total[5m]))Funções de Tempo
avg_over_time(expr[interval]): Calcula a média dos valores no intervalo especificado.
avg_over_time(http_requests_total[5m])sum_over_time(expr[interval]): Calcula a soma dos valores no intervalo especificado.
sum_over_time(http_requests_total[5m])max_over_time(expr[interval]): Retorna o valor máximo no intervalo especificado.
max_over_time(cpu_usage[1h])min_over_time(expr[interval]): Retorna o valor mínimo no intervalo especificado.
min_over_time(memory_usage[1h])Funções de Detecção de Ausência
absent(expr): Retorna 1 se a expressão não retornar nenhum dado, caso contrário retorna nada.
absent(up{job="webserver"})absent_over_time(expr[interval]): Verifica se a métrica esteve ausente durante todo o intervalo.
absent_over_time(up{job="webserver"}[5m])PromQL Avançado
O PromQL oferece recursos avançados para consultas complexas e análises sofisticadas. Esta seção aborda tópicos mais avançados como correspondência de vetores, subconsultas, operadores lógicos e funções especializadas.
Correspondência de Séries Temporais: on(), ignoring(), group_left, group_right
Quando combinamos métricas diferentes (vetor-vetor), muitas vezes precisamos controlar quais labels são usados para fazer o join (união) entre as séries de cada lado da operação. É aqui que entram os modificadores on e ignoring, e os operadores de junção externa group_left e group_right:
-
on(lista_de_labels): Especifica explicitamente quais labels devem ser usados para casar as séries ao aplicar o operador. Todos os demais labels são ignorados no matching (exceto os doonlistados). Exemplo:errors_total / on(instance) requests_totalAqui dizemos: combine séries de
errors_totalerequests_totalque tenham o mesmo valor deinstance. Labels diferentes deinstanceserão ignorados na comparação. Isso é útil se, por exemplo,errors_totaltem um labelstatus="5xx"enquantorequests_totalnão tem o labelstatus. Sem oon(instance), essas séries não casariam por terem conjuntos de labels distintos. -
ignoring(lista_de_labels): O inverso doon. Use todos os labels exceto os listados para fazer o matching. Ou seja, finge que os labels mencionados não existem nos vetores ao procurar pares correspondentes. Exemplo:cpu_usage{cpu="total"} / ignoring(cpu) cpu_quotaSuponha que
cpu_usagetenha um labelcpu(núcleo) e valor"total"para indicar uso total da CPU, enquantocpu_quotanão tem esse label (aplica a todo CPU). Oignoring(cpu)permite desconsiderar essa diferença, casando as séries somente pelos outros labels (por exemplo, pod ou contêiner, se for o caso). -
Junções um-para-muitos (many-to-one): Por padrão, se houver múltiplas séries de um lado que poderiam casar com uma série do outro, a operação não ocorre e o resultado é vazio para evitar ambiguidades. No entanto, às vezes desejamos permitir isso — por exemplo, dividir uma métrica total por número de CPUs, onde a métrica total não tem o label
cpumas a de contagem de CPU tem (múltiplas séries, uma por core). Para isso, usamosgroup_leftougroup_rightem conjunto comon/ignoring:group_left(label1, label2, ...): Indica que as séries do lado esquerdo do operador devem permanecer separadas (muitas) enquanto as do lado direito serão “espalhadas” para casar. Em outras palavras, permite que uma única série do lado direito seja usada para múltiplas do lado esquerdo. Opcionalmente, podemos listar labels que serão copiados do lado direito para o resultado final.group_right(label1, label2, ...): O contrário, mantém o lado direito com muitas séries e espalha o lado esquerdo.
Exemplo (adicionando labels com group_left):
rate(http_requests_total[5m]) * on(instance) group_left(job, environment) upNesse exemplo,
rate(http_requests_total[5m])produz séries talvez com labelsinstancee outros, mas digamos que não tenhajobnemenvironmentexplicitamente (ou queremos copiar doup). A sérieup(métrica de saúde do alvo) temjob,instance, eenvironment. Estamos multiplicando as duas métricas apenas casando porinstance(on(instance)). Como do lado direito (up) há possivelmente apenas uma série por instance (valor 0 ou 1), e do lado esquerdo pode haver múltiplas (por caminho de requisição, status, etc.), usamosgroup_left(job, environment)para dizer: permite que a mesma série deupcase com múltiplas séries de requests do lado esquerdo, e traga os labelsjobeenvironmentdessa série deuppara o resultado final. Assim, o resultado terá a taxa de requests porinstancemas agora enriquecido com os labels de job e environment.Exemplo (many-to-one sem copiar labels):
cpu_usage / on(instance) group_right cpu_countSuponha que
cpu_usage{instance="A"}representa o uso total de CPU (consolidado) em determinada máquina, ecpu_count{instance="A", cpu="0"}ecpu_count{instance="A", cpu="1"}etc. representam 1 para cada CPU física (cada core). Se somarmoscpu_count by (instance)obteríamos o número de CPUs por instância, mas podemos diretamente dividir usando o truque dogroup_right. Aqui, cada série decpu_usage(uma por instancia) será comparada com múltiplas séries decpu_count(uma por CPU). Semgroup_right, não casaria por haver múltiplas séries do lado direito para o mesmo instance. Comgroup_right, permitimos isso e, por não especificar labels a copiar, o resultado herda os labels do lado esquerdo (cpu_usage), e a operação divisão é feita para cada combinação (na prática repetindo o mesmo valor decpu_usagepara cada CPU e dividindo por o respectivocpu_count– o que acaba resultando no mesmo valor para cada CPU). Talvez nesse caso específico fosse melhor já agruparcpu_countantes de dividir, mas esse exemplo ilustra a sintaxe. -
Operador de conjunto
union: PromQL não possui um operador explícito “UNION” nomeado, mas podemos realizar união de resultados simplesmente listando expressões separadas por vírgula em uma consulta. Por exemplo:metric_a, metric_bIsso retorna todas as séries de
metric_ae todas as demetric_b. Não é muito comum em consultas manuais, mas pode ser útil para junção visual.
Resumindo, os modificadores on e ignoring controlam quais labels considerar ao casar séries de métricas diferentes, e group_left/group_right controlam como lidar quando há cardinalidades diferentes (um-para-muitos). Combiná-los corretamente é fundamental para escrever consultas que envolvam múltiplas métricas.
Operadores Lógicos: and, or, unless
Além dos operadores aritméticos e de comparação, PromQL também suporta operadores lógicos para vetores. Esses operadores não criam valores numéricos novos, mas sim filtram ou combinam séries com base em condições booleanas.
-
and: Retém apenas as séries que aparecem em ambos os operandos. Em outras palavras, é uma interseção: uma série do lado esquerdo só passa se existe uma série exatamente igual do lado direito (considerando labels) e vice-versa. O valor resultante de cada série será o valor do lado esquerdo (padrão) ou, se usado como comparador, segue regras de comparador bool. Uso típico: aplicar uma condição a um resultado. Por exemplo:(vector1 comparacao const) and vector1Isso retornaria apenas as séries de
vector1que atendem à comparação (pois o comparador produzirá 1 para as séries que satisfazem, e entãoandmanterá apenas essas). -
or: União de séries. Retorna séries que estão em pelo menos um dos lados. Se a mesma série (mesmos labels) aparece em ambos, o valor resultante será o do lado esquerdo (padrão) ou pode ser modificado com bool se estivermos combinando booleanos. É útil para combinar resultados diferentes. Por exemplo:vector_a or vector_bIsso dá todas as séries de
vector_aevector_b. Se alguma série estiver presente nos dois, aparece uma vez só (com valor devector_a). -
unless: Retém as séries do lado esquerdo a menos que elas também apareçam no lado direito. Equivale a diferença de conjuntos: resultado = esquerda \ direita. (Obs: O lado direito só importa pelos labels, seus valores são ignorados). Por exemplo:up{job="api"} unless up{job="api", region="us-east"}Isso retornaria as séries
updo job “api” que não têm region=“us-east”, ou seja, efetivamente filtra fora todas as instâncias da região us-east.
Os operadores lógicos são avaliados após todos os cálculos numéricos serem feitos. Isso significa que podemos usá-los tanto em métricas brutas quanto em resultados de expressões.
Exemplos práticos combinando comparações e operadores lógicos:
-
Contar instâncias ativas em dois grupos diferentes:
sum(up{job="node"} == 1) or sum(up{job="db"} == 1)Esse exemplo usa
== 1para converter as sériesupem booleanas (1 para up, 0 para down) e soma para contar quantas estão up em cada job. Ooraqui faz a união, retornando duas séries (uma para node e outra para db) com o valor de quantas instâncias estão up em cada. -
Filtrar top 5 de um conjunto e combinar com outro critério:
topk(5, rate(http_requests_total[5m])) and ignoring(instance) (rate(errors_total[5m]) > 0)Esse exemplo hipotético pegaria as 5 maiores taxas de requisição (independente de instância) e então, através do
andcomignoring(instance)e a condição de erros, manteria somente aquelas cujo serviço (ignorando instâncias) está apresentando erros. Bastante específico, mas demonstra o uso combinado:topkproduz séries; a outra parte produz 1/0 para serviços com erro; oand ignoring(instance)casa por serviço e filtra.
Lembrando que, se quisermos comparar valores de uma série com um número e obter diretamente 1 ou 0, podemos usar o modificador bool. Exemplo: vector1 > bool 10 retornaria um vetor com valor 1 para séries onde vector1 > 10 e 0 caso contrário (mantendo os labels). Sem bool, ele retornaria as próprias séries (com seus valores originais) porém filtradas pelas que atendem à condição.
Subconsultas e Análise Temporal Avançada
Counter Range Vectors: Contadores são métricas que apenas aumentam (ou resetam para zero e voltam a aumentar). Exemplos: número total de requisições atendidas, bytes transferidos, etc. Quando consultamos diretamente um counter como range vector, obteremos uma série de pontos que só crescem (com eventuais resets). Para extrair informações úteis (como taxa de eventos por segundo ou aumentos em determinado período) usamos funções especiais:
rate(counter[5m]): Calcula a taxa média por segundo de incremento do contador nos últimos 5 minutos. Essa função já lida corretamente com resets do contador (ignorando as quedas abruptas devido a resets e calculando a taxa considerando isso).irate(counter[5m]): Calcula a taxa instantânea (baseada apenas nos dois pontos mais recentes dentro dos 5 minutos). É mais ruidosa, mas pode reagir mais rapidamente a mudanças repentinas.increase(counter[1h]): Calcula quanto o contador aumentou no último 1 hora. Essencialmente integra a taxa ao longo do período.
Agregação através do tempo (Aggregating Across Time): Às vezes, queremos primeiro agregar os dados e depois analisar a evolução temporal dessa agregação. As subconsultas nos permitem isso. Uma subquery (subconsulta) é quando temos uma expressão do PromQL seguida de um intervalo entre colchetes e possivelmente uma resolução, por exemplo: expr[duração:passo]. Isso faz o Prometheus avaliar expr repetidamente ao longo do intervalo dado, produzindo um range vector como resultado.
Por exemplo, avg_over_time(rate(http_requests_total[1m])[24h:1h]) funciona assim:
- Internamente,
rate(http_requests_total[1m])é avaliado para cada passo de 1h dentro das últimas 24h, gerando a taxa média por minuto calculada a cada hora. - Em seguida,
avg_over_time(...[24h:1h])calcula a média desses 24 valores (um por hora) no tempo atual. Na prática, isso nos daria a média da taxa horária de requisições no dia.
Subconsultas são muito poderosas e foram aprimoradas a partir do Prometheus 2.7. Com elas é possível, por exemplo, calcular tendências, baselines e sazonalidade de forma compacta.
Exemplos avançados de subconsultas e análise de tendências:
-
Tendência de taxa de erro (janela móvel): Calcular a média da taxa de erros em janelas de 1 hora, ao longo das últimas 24 horas:
avg_over_time( rate(http_requests_total{status=~"5.."}[1m])[24h:1h] )Essa consulta gera 24 pontos (taxa de erro média de cada hora nas últimas 24h) e depois calcula a média disso tudo (ou seja, a média diária da taxa de erro). Poderíamos também omitir a função externa para simplesmente visualizar a série das últimas 24 horas e identificar padrões de aumento ou redução de erros ao longo do dia.
-
Baseline de performance (comparação com média histórica): Comparar a performance atual com a média da última semana:
rate(http_requests_total[5m]) / avg_over_time(rate(http_requests_total[5m])[7d])Essa consulta produz uma razão: valores acima de 1 indicam que a taxa atual de requisições está acima da média semanal; valores abaixo de 1, abaixo da média. Isso pode ser útil para identificar desvios significativos de tráfego.
-
Detecção de anomalia sazonal (padrão horário): Comparar o tráfego atual com o padrão do último dia:
rate(http_requests_total[5m]) / avg_over_time(rate(http_requests_total[5m])[24h:1h])Aqui, o denominador
avg_over_time(...[24h:1h])produz a média da taxa em cada hora do dia anterior. Dividindo a taxa atual por esse valor da mesma hora ontem, podemos identificar se o tráfego está anormalmente alto ou baixo para este horário do dia. -
Diferença diária (subconsulta com offset): Para calcular a diferença em uma métrica entre hoje e ontem, podemos usar
offset. Exemplo:my_metric - my_metric offset 1dIsso resulta em quanto
my_metricvariou em comparação com exatamente 24 horas atrás. -
Soma acumulada (exemplo de subconsulta):
sum(my_counter) - sum(my_counter) offset 1dEste exemplo soma o contador
my_counter(provavelmente de várias instâncias) e subtrai o valor de 1 dia atrás, mostrando o incremento total em um dia. Essa é outra forma de calcular algo similar aincrease(my_counter[1d]).
Em todos esses casos, as subconsultas [ ... ] estão permitindo observar ou reutilizar resultados ao longo do tempo dentro de uma única expressão.
Funções Avançadas e Especializadas
Algumas funções do PromQL são menos conhecidas, mas podem ser extremamente poderosas em cenários específicos:
-
resets(counter[interval]): Conta quantas vezes um contador “resetou” (voltou a zero) no período. Útil para detectar reinicializações de aplicativos ou problemas de coleta. Exemplos:resets(http_requests_total[5m])Contaria quantos resets ocorreram no
http_requests_totalnos últimos 5 minutos. Se esse número for > 0 constantemente, pode indicar que o serviço está reiniciando frequentemente (se o contador for interno ao serviço) ou que há overflow de contadores. -
changes(series[interval]): Conta quantas vezes o valor de uma série mudou durante o intervalo. Isso vale para qualquer métrica (não apenas counters). Pode indicar instabilidade ou flapping. Exemplo:changes(process_start_time_seconds[5m]) > 0O exemplo acima retornaria 1 para instâncias cujo
process_start_time_seconds(normalmente um timestamp de início do processo) tenha mudado nos últimos 5 minutos — ou seja, o processo reiniciou nesse período. -
predict_linear(series[interval], passos_no_futuro): Realiza uma extrapolação linear do valor da série com base na tendência nos últimos intervalos e prevê o valor daqui a X segundos (informado empassos_no_futuro). Útil para prever quando algo alcançará um certo limite. Exemplo:predict_linear(node_filesystem_free_bytes[1h], 3600) < 0Poderia ser usado para alertar se a tendência de queda do espaço livre prevê que em 1 hora (
3600segundos) o espaço chegaria a zero. -
holt_winters(series[interval], sf, tf): Embora mais comum no Graphite, o PromQL também tem uma função de previsão chamadaholt_winters(Holt-Winters, série temporal com tendência e sazonalidade). Aceita uma série (geralmente resultado de subconsulta) e realiza suavização exponencial dupla. No entanto, essa função é raramente usada diretamente em alertas, servindo mais para visualização de tendências suavizadas. -
Funções para histogramas nativos (Prometheus 3.x):
histogram_count()ehistogram_sum()– Retornam, respectivamente, a contagem total e a soma total das observações de histogramas (clássicos ou nativos). Para histogramas clássicos, esses usam as séries_counte_suminternas; para nativos, usam os valores codificados.histogram_avg()– Computa a média dos valores observados em cada histograma, equivalente ahistogram_sum/histogram_count.histogram_fraction(lower, upper, hist)– Estima a fração de observações dentro do intervalo[lower, upper]para cada histograma. Útil, por exemplo, para calcular Apdex (fração de requisições abaixo de um certo limiar de latência).
Lembrando que algumas dessas funções mais novas podem requerer flags experimentais, dependendo da versão do Prometheus.
PromQL na Prática
O PromQL é a linguagem de consulta do Prometheus que permite extrair insights valiosos das métricas coletadas. Vamos explorar exemplos práticos de consultas comuns para uso diário em monitoramento.
Consultas Básicas de Disponibilidade
Verificar se todos os targets estão up:
up == 1Contar quantos targets estão down:
count(up == 0)Taxa de disponibilidade por job:
avg(up) by (job)Métricas de Sistema (Node Exporter)
CPU médio por instância:
avg(rate(node_cpu_seconds_total{mode="user"}[5m])) by (instance)Uso de memória em porcentagem:
(node_memory_MemTotal_bytes - node_memory_MemAvailable_bytes) / node_memory_MemTotal_bytes * 100Uso de disco por filesystem:
(node_filesystem_size_bytes - node_filesystem_free_bytes) / node_filesystem_size_bytes * 100Taxa de I/O de disco:
rate(node_disk_io_time_seconds_total[5m])Métricas de Aplicação Web
Taxa de requisições por segundo (QPS):
rate(http_requests_total[5m])Taxa de erro por endpoint:
rate(http_requests_total{status=~"5.."}[5m])Latência p95 (percentil 95):
histogram_quantile(0.95, sum(rate(http_request_duration_seconds_bucket[5m])) by (le))Latência p99 (percentil 99):
histogram_quantile(0.99, sum(rate(http_request_duration_seconds_bucket[5m])) by (le))Tempo de resposta médio:
rate(http_request_duration_seconds_sum[5m]) / rate(http_request_duration_seconds_count[5m])Métricas de Banco de Dados
Conexões ativas do PostgreSQL:
pg_stat_database_numbackendsTaxa de transações por segundo:
rate(pg_stat_database_xact_commit[5m]) + rate(pg_stat_database_xact_rollback[5m])Tamanho de tabelas (PostgreSQL):
pg_stat_user_tables_size_bytesMétricas de Container/Kubernetes
CPU por pod:
sum(rate(container_cpu_usage_seconds_total{container!=""}[5m])) by (pod)Memória por pod:
sum(container_memory_usage_bytes{container!=""}) by (pod)Pods por namespace:
count(kube_pod_info) by (namespace)Alertas Comuns
Alerta de CPU alta:
100 - (avg(irate(node_cpu_seconds_total{mode="idle"}[5m])) by (instance) * 100) > 80Alerta de memória alta:
(node_memory_MemTotal_bytes - node_memory_MemAvailable_bytes) / node_memory_MemTotal_bytes * 100 > 85Alerta de disco cheio:
(node_filesystem_size_bytes - node_filesystem_free_bytes) / node_filesystem_size_bytes * 100 > 90Alerta de latência alta:
histogram_quantile(0.95, sum(rate(http_request_duration_seconds_bucket[5m])) by (le)) > 1Alerta de taxa de erro alta:
rate(http_requests_total{status=~"5.."}[5m]) / rate(http_requests_total[5m]) > 0.05Consultas Avançadas
Top 5 instâncias com maior CPU:
topk(5, 100 - (avg(irate(node_cpu_seconds_total{mode="idle"}[5m])) by (instance) * 100))Soma de métricas por região:
sum(rate(http_requests_total[5m])) by (region)Diferença de métricas entre períodos:
increase(http_requests_total[1h]) - increase(http_requests_total[1h] offset 1h)Métrica com label dinâmico:
rate(http_requests_total{endpoint=~"/api/.*"}[5m])Dicas de Performance
Use intervalos apropriados:
- Para alertas:
[5m]ou[1m] - Para dashboards:
[1h]para tendências - Evite
[24h]em consultas frequentes
Prefira rate() sobre irate() para alertas:
# Bom para alertas (mais estável)
rate(http_requests_total[5m])
# Melhor para dashboards (mais responsivo)
irate(http_requests_total[5m])Agregue quando possível:
# Em vez de somar muitas séries
sum(rate(http_requests_total[5m])) by (job)
# Evite isso em métricas com alta cardinalidade
sum(rate(http_requests_total[5m]))Exemplos de Recording Rules
Regra para QPS agregado:
groups:
- name: recording_rules
rules:
- record: job:http_requests:rate5m
expr: sum(rate(http_requests_total[5m])) by (job)Regra para latência p95:
- record: job:http_request_duration_seconds:p95
expr: histogram_quantile(0.95, sum(rate(http_request_duration_seconds_bucket[5m])) by (le, job))Dica: Use recording rules para pré-calcular consultas complexas e frequentes. Isso melhora a performance e reduz a carga no Prometheus.
Instrumentação direta: exemplos por linguagem
Agora vejamos como instrumentar aplicações escritas em algumas linguagens populares. A ideia geral em qualquer linguagem é: instalar a biblioteca cliente do Prometheus, criar métricas (counters, gauges, etc.) em pontos estratégicos do código, e expor um endpoint HTTP /metrics onde essas métricas são servidas (em formato de texto). O Prometheus então coleta nesse endpoint.
Java (Micrometer / Cliente Java do Prometheus)
Em Java, uma abordagem comum é usar o Micrometer – uma biblioteca de instrumentação que suporta múltiplos backends (Prometheus, Graphite, etc.). O Micrometer foi adotado pelo Spring Boot, por exemplo, facilitando a exposição de métricas. Passos básicos:
-
Dependências: Adicione ao seu projeto (pom.xml ou build.gradle) a dependência do Micrometer e do registry Prometheus. Exemplo (Maven):
<dependency> <groupId>io.micrometer</groupId> <artifactId>micrometer-core</artifactId> <version>1.10.4</version> </dependency> <dependency> <groupId>io.micrometer</groupId> <artifactId>micrometer-registry-prometheus</artifactId> <version>1.10.4</version> </dependency> -
Registrar métricas: Em sua aplicação, configure um
MeterRegistrydo Prometheus e registre métricas. Por exemplo, em uma classe de configuração Spring:@Bean PrometheusMeterRegistry prometheusRegistry() { return new PrometheusMeterRegistry(PrometheusConfig.DEFAULT); }Você pode então criar contadores, gauges, etc. usando esse registry:
Counter requestCount = Counter.builder("myapp_requests_total") .description("Total de requisições") .register(prometheusRegistry()); // Usar requestCount.inc(); em pontos apropriados do códigoOu usar anotações/filtros prontos do Spring Boot Actuator que medem tempos de resposta automaticamente.
-
Expor endpoint /metrics: Se estiver usando Spring Boot Actuator, habilite a endpoint Prometheus. No application.properties:
management.endpoints.web.exposure.include=prometheus management.endpoint.prometheus.enabled=trueIsso fará o Actuator expor
/actuator/prometheuscom as métricas no formato Prometheus. O Prometheus pode então fazer scrape nessa URL. (Alternativamente, sem Spring, você poderia iniciar um HTTP server manualmente que responda comprometheusRegistry.scrape()output). -
Verificar métricas: Ao rodar a aplicação, acesse http://localhost:8080/actuator/prometheus (por exemplo) e você verá todas as métricas registradas, inclusive padrões do JVM (o Micrometer já fornece métricas de memória, CPU, GC, etc. por padrão) e as personalizadas que você adicionou.
Em resumo, no Java/Spring o processo pode ser muito simples aproveitando frameworks existentes. Para outras aplicações Java sem Spring, existe também o cliente Java do Prometheus (simpleclient) onde você manualmente gerencia as métricas e HTTP endpoint.
JavaScript/Node.js
No Node.js podemos usar o pacote prom-client para instrumentação:
-
Instalar pacote:
npm install prom-client. -
Criar métricas no código: Por exemplo, vamos medir o tempo de resposta de uma rota Express:
const express = require('express'); const promClient = require('prom-client'); const app = express(); // Cria um histogram para tempos de resposta em segundos const httpResponseHist = new promClient.Histogram({ name: 'myapp_http_response_duration_seconds', help: 'Tempo de resposta das requisições HTTP (segundos)', labelNames: ['route', 'method'] });Aqui usamos um Histogram (poderia ser Summary também). Antes de enviar a resposta na rota, registramos a observação:
app.get('/example', (req, res) => { const end = httpResponseHist.startTimer({ route: '/example', method: 'GET' }); // ... lógica da rota ... res.send("Hello World"); end(); // marca o fim do timer e observa a duração no histogram });O prom-client possui métodos convenientes para medir duração com
Histogram.startTimer()que retorna uma função para encerrar e registrar. -
Expor as métricas: Precisamos servir as métricas via HTTP para o Prometheus. Podemos criar um endpoint
/metrics:app.get('/metrics', async (req, res) => { res.set('Content-Type', promClient.register.contentType); res.end(await promClient.register.metrics()); });Isso coleta todas as métricas registradas e retorna no formato de texto padrão.
-
Iniciar server: Por fim, inicie seu servidor Node (por ex,
app.listen(3000)). Então a URL http://localhost:3000/metrics mostrará as métricas. -
Configurar Prometheus: Adicione no
prometheus.ymlum job apontando para o serviço Node, porta 3000 (ou a porta usada) e path/metrics. Exemplo:scrape_configs: - job_name: 'my-nodeapp' static_configs: - targets: ['my-node-host:3000'](Se o Node está no mesmo Docker Compose do Prometheus, pode usar o nome de serviço do container e porta.)
A partir daí, o Prometheus coletará as métricas do seu app Node. Você poderá consultar coisas como rate(myapp_http_response_duration_seconds_count[5m]) ou histogram_quantile(0.9, rate(myapp_http_response_duration_seconds_bucket[5m])) para ver percentis de latência.
Python (Flask, etc.)
Em Python, há o pacote prometheus_client. Exemplo integrando com Flask:
-
Instalação:
pip install prometheus_client. -
Criação de métricas: Digamos que queremos contar requisições e medir duração. Podemos usar um Histogram ou Summary. Aqui um Summary:
from flask import Flask, request from prometheus_client import Summary, Counter, start_http_server app = Flask(__name__) REQUEST_TIME = Summary('myapp_request_processing_seconds', 'Tempo de processamento por rota', ['endpoint']) REQUEST_COUNT = Counter('myapp_requests_total', 'Total de requisições', ['endpoint', 'http_status'])Decoramos a rota para coletar métricas:
@app.route("/example") def example(): with REQUEST_TIME.labels(endpoint="/example").time(): # inicia timer automático # ... lógica do endpoint ... response = "Hello World" REQUEST_COUNT.labels(endpoint="/example", http_status=200).inc() return responseO
Summary.time()funciona como context manager medindo o tempo dentro do bloco. Também incrementamos um counter de requests totais por endpoint e status. -
Expor métricas: Podemos fazer de duas formas – ou usamos o servidor HTTP interno do prometheus_client ou integramos com Flask. Uma maneira simples: iniciar um thread do servidor metrics separado:
if __name__ == "__main__": start_http_server(8000) # inicia servidor em porta 8000 app.run(host="0.0.0.0", port=5000)
O start_http_server(8000) fará com que em http://localhost:8000/metrics tenhamos as métricas (note: ele por default expõe em /metrics automaticamente). Nesse caso, o Prometheus deve apontar para porta 8000 do app.
Alternativamente, há integração para Flask (via middleware) que poderia expor /metrics no próprio Flask app.
- Prometheus config: Similar aos anteriores, adicionar job apontando para o endpoint do metrics (host e porta usados).
Após esses passos, seu app Python estará fornecendo métricas. Você pode conferir acessando http://localhost:8000/metrics e vendo as séries nomeadas myapp_request_processing_seconds_* e myapp_requests_total entre outras (o client lib Python também expõe métricas padrão do processo Python como uso de memória do processo, CPU, etc.).
Ferramentas legadas e fechadas
Uma dificuldade comum é monitorar sistemas legados ou softwares proprietários que não oferecem métricas no formato Prometheus. Nesses casos, há alguns padrões de solução:
-
Exporters externos: Como já mencionado, se existir um exporter compatível (oficial ou da comunidade) para aquela ferramenta, ele é o caminho mais fácil – rodar o exporter e configurá-lo como alvo. Por exemplo, para monitorar um servidor Oracle proprietário, pode haver um exporter que conecta no Oracle e extrai estatísticas via queries.
-
Bridges personalizadas: Caso não exista um exporter pronto, podemos criar um processo intermediário (bridge) que consulta a ferramenta legada de alguma forma (API REST, CLI, leitura de arquivos de log) e expõe resultados em /metrics. Essencialmente, isso é escrever um pequeno exporter sob medida. Ferramentas de script como Python facilitam isso – você coleta os dados e usa
prometheus_clientpara expor. -
Integrações via gateway ou plugins: Alguns ambientes possuem hooks para métricas. Por exemplo, aplicações .NET legadas podem exportar contadores no Windows Performance Counters – aí usar o Windows Exporter para pegá-los. Em casos extremos, você pode usar o Pushgateway como ponte: o sistema legado faz push de alguma métrica básica para o gateway (não ideal, mas possível).
Em resumo, sempre é possível integrar algo ao Prometheus, ainda que indiretamente. A comunidade já produziu exporters para muitos sistemas fechados (WebLogic, SAP, etc.). E como último recurso, extrair dados e expor manualmente não é tão complexo graças às bibliotecas cliente disponíveis.
Alertmanager
O Alertmanager complementa o Prometheus no tratamento de alertas. Enquanto o Prometheus detecta condições de alerta (com base nas métricas e regras definidas), ele delega ao Alertmanager a função de envio de notificações e gerenciamento desses alertas. Isso inclui agregar alertas similares, evitar duplicações, silenciar alertas durante manutenção, e encaminhá-los para canais apropriados (e-mail, sistemas de chat, PagerDuty, etc.).
Alta Disponibilidade: O Alertmanager suporta configuração em cluster para alta disponibilidade. Quando múltiplas instâncias do Alertmanager estão ativas, elas se comunicam entre si para deduplicar alertas vindos de dois Prometheus idênticos, garantindo que apenas uma notificação seja enviada mesmo quando múltiplas fontes detectam o mesmo problema.
Como funciona: você define no Prometheus regras de alerta (no arquivo de configuração ou separado) com expressões PromQL que identificam situações problemáticas. Por exemplo: “se a métrica
upde um servidor for 0 por 5 minutos, dispare alerta”.
Quando a condição é verdadeira, o Prometheus gera um evento de alerta e o envia para o Alertmanager (que está configurado na seção alerting do prometheus.yml).
O Alertmanager então aplica suas próprias regras de roteamento: por exemplo, enviar alertas de severidade crítica para um webhook do Slack e para email da equipe X, alertas menos graves só para email, etc…
Exemplo prático: Vamos configurar um alerta de servidor fora do ar com notificação no Slack.
- Definir regra de alerta (Prometheus): Crie um arquivo
alert.rules.yml:
groups:
- name: instance_down
rules:
- alert: InstanceDown
expr: up == 0
for: 1m
labels:
severity: critical
annotations:
summary: "Instância {{ $labels.instance }} fora do ar"
description: "O alvo {{ $labels.instance }} não respondeu às coletas por mais de 1 minuto."Essa regra verifica a métrica up de todos os alvos; se qualquer um estiver com valor 0 (significa alvo inacessível) por 1 minuto contínuo, aciona o alerta InstanceDown com severidade critical. As anotações fornecem um resumo e descrição usando templating (inserindo o label instance do alvo problemático).
- Incluir regra e Alertmanager na config do Prometheus: No
prometheus.yml, adicionar:
rule_files:
- "alert.rules.yml"
alerting:
alertmanagers:
- static_configs:
- targets: ['alertmanager:9093']Aqui presumimos que o Alertmanager está rodando e acessível no endereço alertmanager:9093 (no Docker Compose, por ex.). O Prometheus agora carrega as regras de alerta e sabe para onde enviar notificações.
- Configurar o Alertmanager (alertmanager.yml): Exemplo mínimo para Slack:
route:
group_by: ['alertname']
receiver: 'time-slack'
receivers:
- name: 'time-slack'
slack_configs:
- api_url: 'https://hooks.slack.com/services/T000/B000/XXXXX' # Webhook do Slack
channel: '#alerts'
send_resolved: true
title: "{{ range .Alerts }}{{ .Annotations.summary }}{{ end }}"
text: "{{ range .Alerts }}{{ .Annotations.description }}{{ end }}"Esse config muito básico diz: todos alertas (não importa o grupo_by, etc.) irão para o receptor nomeado ’time-slack’, que tem um slack_config apontando para um webhook do Slack no canal #alerts. O title e text da mensagem aproveitam as anotações definidas na regra (summary e description).
O valor send_resolved: true indica para notificar também quando o alerta for resolvido.
Em produção, o Alertmanager pode ter rotas mais elaboradas – por exemplo, roteando com base em labels de alerta (team=A vai para equipe A, severidade critical pode mandar SMS, etc.), escalonamento, agrupamento por determinados campos (como agrupar todos alertas do mesmo datacenter numa só notificação), etc.
- Executar e testar: Rode o Alertmanager com esse config (no Docker ou binário). Quando um alerta InstanceDown ocorrer, o Prometheus vai enviar para o Alertmanager, que em seguida usará a integração Slack para postar no canal configurado uma mensagem com título “Instância X fora do ar” e descrição com detalhes.
Esse foi um exemplo focado em Slack, mas o Alertmanager suporta muitos outros receivers: e-mail (SMTP), PagerDuty, OpsGenie, VictorOps, Webhooks genéricos, entre outros. Com ele, você ganha flexibilidade para gerenciar o “barulho” de alertas: por exemplo, suprimir alertas filhos quando um pai já ocorreu (inhibition), ou silenciar certos alertas durante janelas de manutenção planejada.
Observação: O Alertmanager não é obrigatório – você pode rodar o Prometheus sem ele se não precisar de notificações externas. Porém, para qualquer ambiente de produção, é altamente recomendado configurá-lo para não depender de ficar olhando a página /alerts manualmente. Em outro artigo abordaremos em detalhes boas práticas de configuração do Alertmanager.
Alertmanager Avançado: Silencing e Inhibition
Em ambientes de produção com muitos alertas, o “alert fatigue” (fadiga de alertas) pode ser um problema sério. O Alertmanager oferece funcionalidades avançadas para gerenciar esse cenário: silencing (silenciamento) e inhibition (inibição).
Silencing
O silencing permite suprimir temporariamente alertas específicos, geralmente durante janelas de manutenção planejada. Isso evita spam desnecessário quando você já sabe que um serviço estará indisponível.
Exemplo de configuração de silence:
# Via API do Alertmanager (POST /api/v1/silences)
{
"matchers": [
{
"name": "alertname",
"value": "InstanceDown",
"isRegex": false
},
{
"name": "instance",
"value": "web-server-01:9100",
"isRegex": false
}
],
"startsAt": "2023-12-01T10:00:00Z",
"endsAt": "2023-12-01T12:00:00Z",
"createdBy": "admin",
"comment": "Manutenção programada do servidor web-01"
}Silencing via interface web:
O Alertmanager oferece uma interface web em /silences onde você pode criar silences interativamente, especificando:
- Matchers: Labels que identificam os alertas a silenciar
- Duração: Período de silenciamento (início e fim)
- Comentário: Justificativa para o silence
Inhibition
A inhibition permite suprimir alertas secundários quando um alerta primário já está ativo. Por exemplo, se um servidor caiu (alerta crítico), não faz sentido alertar sobre “disco quase cheio” ou “alta latência” na mesma instância.
Exemplo de configuração de inhibition:
inhibit_rules:
# Se um alerta critical estiver ativo, suprimir warnings da mesma instância
- source_match:
severity: 'critical'
target_match:
severity: 'warning'
equal: ['instance', 'job']
# Se um datacenter estiver down, suprimir alertas de serviços internos
- source_match:
alertname: 'DatacenterDown'
target_match:
severity: 'warning'
equal: ['datacenter']
# Se CPU estiver 100%, suprimir alertas de alta latência
- source_match:
alertname: 'HighCPUUsage'
severity: 'critical'
target_match:
alertname: 'HighLatency'
equal: ['instance']Casos de uso comuns:
- Alertas de infraestrutura: Se um rack/datacenter caiu, suprimir alertas de serviços que dependem dele
- Alertas de aplicação: Se um serviço crítico está down, não alertar sobre métricas secundárias
- Alertas de dependência: Se um banco de dados está inacessível, suprimir alertas de aplicações que dependem dele
Routing Avançado
O Alertmanager permite roteamento sofisticado baseado em labels de alerta:
route:
group_by: ['alertname', 'cluster', 'service']
group_wait: 30s
group_interval: 5m
repeat_interval: 4h
routes:
# Alertas críticos vão para PagerDuty + Slack
- match:
severity: critical
receiver: 'pager-duty-critical'
continue: true # Continua para o próximo receiver
# Alertas críticos também vão para Slack
- match:
severity: critical
receiver: 'slack-critical'
# Alertas de infraestrutura vão para equipe de infra
- match:
job: node
receiver: 'infra-team'
# Alertas de aplicação vão para equipe de dev
- match:
job: app
receiver: 'dev-team'
# Default: todos os outros alertas vão para Slack geral
- receiver: 'slack-general'
receivers:
- name: 'pager-duty-critical'
pagerduty_configs:
- service_key: 'your-pagerduty-key'
- name: 'slack-critical'
slack_configs:
- api_url: 'https://hooks.slack.com/services/...'
channel: '#alerts-critical'
- name: 'infra-team'
slack_configs:
- api_url: 'https://hooks.slack.com/services/...'
channel: '#infra-alerts'
- name: 'dev-team'
slack_configs:
- api_url: 'https://hooks.slack.com/services/...'
channel: '#dev-alerts'
- name: 'slack-general'
slack_configs:
- api_url: 'https://hooks.slack.com/services/...'
channel: '#monitoring'Recursos avançados:
- Agrupamento inteligente:
group_byagrupa alertas similares em uma notificação - Tempo de espera:
group_waitaguarda antes de enviar o primeiro alerta do grupo - Intervalo de repetição:
repeat_intervaldefine quando reenviar alertas não resolvidos - Roteamento condicional:
continue: truepermite múltiplos receivers para o mesmo alerta
PushGateway
O Pushgateway é um componente auxiliar do ecossistema Prometheus que permite coletar métricas via modelo push em situações específicas. A ideia é que certos jobs ou aplicativos efêmeros, que não têm como serem raspados diretamente (por exemplo, um script cron que executa e termina rapidamente), possam empurrar suas métricas para um gateway intermediário. O Prometheus então coleta essas métricas do Pushgateway posteriormente.
Funciona assim: o job de curta duração (ou qualquer processo que não viva tempo suficiente para ser raspado) envia um HTTP POST para o Pushgateway com suas métricas no formato Prometheus. O Pushgateway armazena essas métricas em memória e as expõe em seu próprio /metrics. O Prometheus configura um scrape no Pushgateway, coletando tudo que estiver lá.
Porém, é importante entender que o Pushgateway deve ser usado com moderação e propósito claro. Ele não é um agente genérico para substituir o modelo pull. Alguns pontos de atenção destacados pela documentação oficial:
- Se múltiplas instâncias usam um mesmo Pushgateway, ele vira um ponto central de falha e potencial gargalo.
- Você perde a detecção automática de down (já que as métricas são push, o Prometheus não sabe se um job não está rodando ou só não teve métricas recentes).
- O Pushgateway não expira automaticamente séries que foram enviadas. Uma vez que uma métrica é empurrada, ela ficará lá até ser sobrescrita ou manualmente apagada via API do Pushgateway. Isso significa que métricas de jobs antigos podem ficar persistindo como “fantasmas”, exigindo que você gerencie remoção ou inclusão de algum label de instance para distingui-las.
Devido a esses aspectos, o uso recomendado do Pushgateway é capturar resultados de jobs batch de nível de serviço – isto é, trabalhos que não pertencem a uma única máquina ou instância específica, mas sim algo como “um script de limpeza de banco que roda uma vez por dia”.
Nesse caso, o job emite (push) uma métrica do tipo “usuarios_deletados_total{job=“cleanup”} 123” e termina. O Pushgateway guarda esse valor.
O Prometheus, ao raspar, terá essa informação agregada do job. Como esse tipo de job não tem um “endpoint” próprio para scrap, o Pushgateway serve como cache.
Para outros cenários, onde o push é considerado porque há firewall/NAT impedindo scrapes, a documentação sugere alternativas melhores – como rodar Prometheus perto dos alvos (dentro da rede) ou usar algo como o PushProx para atravessar firewalls mantendo o modelo pull. E para jobs cron por máquina, que têm contexto de host, recomenda-se usar o Node Exporter Textfile Collector (escrever métricas em um arquivo que o Node Exporter lê), ao invés do Pushgateway.
Resumindo: o Pushgateway é útil, mas somente em casos específicos. Evite usá-lo para coletar métricas de serviços normais (isso seria “usar push por preguiça”, e acarretaria problemas de dados stale e falta de detecção de falha). Use-o para jobs batch pontuais, e mesmo assim, sem abusar – lembre-se de limpar métricas antigas se necessário, ou projetar os labels de modo que cada job substitua seu próprio valor sem acumular lixo.
Federação
A federação no Prometheus permite que uma instância do Prometheus (geralmente chamada de federadora ou global) faça scrape em endpoints de outras instâncias do Prometheus (federadas) para obter um subconjunto de suas métricas.
Em outras palavras, é uma forma de hierarquizar o monitoramento: por exemplo, você pode ter um Prometheus por data center coletando tudo localmente, e um Prometheus global que apenas busca métricas já agregadas de cada data center para ter uma visão geral corporativa.
Existem dois casos de uso principais para federação:
-
Agregação hierárquica: como no exemplo acima, onde cada Prometheus local faz o trabalho pesado e calcula agregados (soma de CPU por datacenter, latência média de serviço X por datacenter, etc.), e o Prometheus global só extrai essas séries agregadas prontas. Isso dá uma visão do todo sem sobrecarregar a instância global com todas as séries detalhadas.
-
Checagens cruzadas ou seletivas: Puxar algumas poucas métricas de outra instância para comparações. Exemplo: você tem um Prometheus dedicado a HAProxy e outro para um app front-end, pode federar a métrica de QPS do HAProxy no Prometheus do front-end para checar se ambos observam o mesmo tráfego. Normalmente, isso é usado até mesmo apenas para alertas (você pode configurar alertas usando essas poucas métricas federadas).
Quando NÃO usar federação: a tentação de federar tudo de todos os Prometheus em um “super Prometheus” central deve ser evitada. Pegar todas as séries de instâncias filhas e centralizar em uma só instância global traz vários problemas:
- Escalabilidade limitada: O desempenho do Prometheus é limitado pelos recursos de um único nó (não escala horizontalmente). Se você puxa tudo para um só servidor global, no fim do dia você está limitado ao throughput e memória de uma máquina. Isso anula a distribuição de carga que múltiplas instâncias proporcionam.
- Performance e carga duplicada: Além de sobrecarregar a instância global ao ter que armazenar e consultar tudo, a própria operação de federação (expor /federate e responder a scraping) gera carga nas instâncias filhas. Se a consulta federada não for focada (usar expressões match[] genéricas demais), pode consumir muitos recursos para as instâncias fonte servirem esses dados.
- Confiabilidade reduzida: Você adiciona um ponto extra de falha. Se o link entre uma instância local e a global cair, a instância global “fica cega” àquele segmento. E pior, se você centralizou a avaliação de certos alertas só no global, pode ficar sem alertas (falso negativo) caso o global perca conexão com os locais. A recomendação de especialistas é sempre que possível avaliar alertas o mais localmente possível – por exemplo, um alerta “serviço X caiu” deve ser definido no Prometheus que coleta serviço X, não em um global distante, exatamente para não depender de rede.
- Delay e possíveis inconsistências: A federação não é instantânea; há latência entre um dado ser coletado no Prometheus filho e ser federado pelo pai. Além disso, condições de corrida podem fazer o global perder algumas amostras ou ver valores ligeiramente diferentes (por exemplo, contadores que resetaram podem parecer estranhos). Para uns poucos agregados isso é tolerável, mas se você federar tudo e depender disso para alertar, pode ter sutilezas indesejadas.
- Complexidade de configuração e segurança: É mais complexo gerenciar dois níveis de Prometheus, com configurações de match[], externas labels únicas por instância, etc. Também é necessário expor o endpoint /federate das instâncias filhas – o que pode ampliar a superfície de ataque ou requerer configurações TLS, autenticação, caso atravesse redes não confiáveis.
Em razão desses fatores, a federação deve ser usada apenas para casos de uso bem planejados (tipicamente agregações de baixo volume ou métricas específicas). Não é a solução adequada para retenção de longo prazo nem para alta disponibilidade.
NOTA: Para necessidades de escalabilidade horizontal e armazenamento de longo prazo, surgiram outros projetos que complementam o Prometheus, como Thanos, Cortex e Mimir (Grafana Labs). Essas soluções armazenam as séries em storage distribuído (objeto, bigtable, etc.) e permitem “juntar” múltiplas instâncias como se fossem uma só, suportando consultas globais e retenção virtualmente infinita. Exploraremos essas alternativas em outro artigo, mas adianta-se que elas resolvem muitos dos problemas de tentar usar federação pura para esses fins.
Remote Write e Remote Read
O Prometheus pode ser configurado para enviar suas métricas em tempo real para bancos externos (remote write) e buscar dados históricos de outros sistemas (remote read). Essa funcionalidade é fundamental para integração com soluções de armazenamento de longo prazo, compliance e análise de dados.
Remote Write
O remote write permite que o Prometheus envie amostras coletadas para sistemas externos em tempo real, mantendo uma cópia local. Isso é útil para:
- Retenção de longo prazo: Enviar dados para sistemas como InfluxDB, TimescaleDB, ou soluções cloud
- Compliance e auditoria: Manter métricas por meses/anos para requisitos regulatórios
- Machine Learning: Integrar com plataformas de ML para análise preditiva
- Correlação de dados: Combinar métricas com logs e traces em sistemas unificados
Exemplo de configuração:
remote_write:
- url: "https://longterm.example.com/api/v1/write"
basic_auth:
username: "prometheus"
password: "password"
write_relabel_configs:
- source_labels: [__name__]
regex: 'node_.*'
action: keep
queue_config:
max_samples_per_send: 1000
max_shards: 30
capacity: 2500Configurações importantes:
url: Endpoint do sistema de destinobasic_auth: Autenticação básica (também suporta TLS)write_relabel_configs: Filtros para enviar apenas métricas específicasqueue_config: Configurações de buffer e performance
Remote Read
O remote read permite que o Prometheus busque dados históricos de sistemas externos, como se fossem parte do seu TSDB local. Isso é útil para:
- Consultas históricas: Acessar dados antigos sem manter tudo localmente
- Migração de dados: Transição gradual entre sistemas de armazenamento
- Análise retrospectiva: Investigar incidentes passados com dados completos
Exemplo de configuração:
remote_read:
- url: "https://longterm.example.com/api/v1/read"
basic_auth:
username: "prometheus"
password: "password"
read_recent: true
required_matchers:
- label: "job"
value: "node"Casos de Uso Típicos
1. Integração com Grafana Cloud:
remote_write:
- url: "https://prometheus-prod-XX-XXX.grafana.net/api/prom/push"
basic_auth:
username: "12345"
password: "glc_eyJvIjoiOTk5OTkiLCJuIjoiYWRtaW4iLCJpIjoiMTIzNDU2Nzg5MCJ9"2. Envio para InfluxDB:
remote_write:
- url: "http://influxdb:8086/api/v2/prom/write?org=myorg&bucket=prometheus"
basic_auth:
username: "admin"
password: "password"3. Múltiplos destinos:
remote_write:
- url: "https://backup-storage.example.com/write"
write_relabel_configs:
- source_labels: [__name__]
regex: '.*'
action: keep
- url: "https://ml-platform.example.com/metrics"
write_relabel_configs:
- source_labels: [__name__]
regex: 'app_.*'
action: keepImportante: Remote write/read não substitui o armazenamento local do Prometheus. O TSDB local continua sendo usado para consultas recentes e alertas. O remote write é aditivo - você mantém os dados locais e envia uma cópia para sistemas externos.
Under the Hood
Nesta seção, vamos dissecar o funcionamento interno do armazenamento de dados do Prometheus – o Time Series Database (TSDB) local – e entender por que ele consome recursos como consome.
Quando instalamos o Prometheus, uma pasta de dados (por padrão chamada data/) é usada para persistir as séries temporais coletadas. Dentro dela, os dados são organizados em blocos de tempo fixo. Por padrão, cada bloco cobre 2 horas de métricas. Após duas horas de coleta, o Prometheus fecha aquele bloco e inicia outro.
Periodicamente, vários blocos menores podem ser compactados em blocos maiores (por exemplo, 5 blocos de 2h podem ser mesclados num bloco de 10h de dados, e assim por diante). A estrutura de arquivos típica em data/ é assim (exemplo simplificado):
data/
├── 01GZY5ABCD.../ # pasta de um bloco de dados
│ ├── meta.json # metadados do bloco
│ ├── index # índice para busca das séries no bloco
│ ├── chunks/ # pedaços contendo os samples comprimidos
│ └── tombstones # (pode estar vazio) marcações de deleção
├── 01GZY1WXYZ.../ # outro bloco (mais antigo, por ex)
│ └── ...
├── chunks_head/ # chunks do bloco "head" atual (em uso)
└── wal/ # Write-Ahead Log (log de escrita recente)
├── 00000000
├── 00000001
└── checkpoint.000001/ ...Cada bloco de 2h é identificado por um ULID (ID único lexicograficamente ordenável) que compõe o nome da pasta. Dentro de um bloco, temos:
- meta.json: arquivo JSON com metadados do bloco (faixa de tempo coberta, stats de quantas séries/amostras contém, histórico de compactação, etc.).
- index: arquivo de índice invertido para permitir procurar séries rapidamente pelo nome e labels, e localizar em quais chunks estão seus dados.
- chunks/: diretório contendo os arquivos binários de chunks de dados. Os chunks são os blocos comprimidos de amostras das séries. Cada arquivo (nomeado como 000001, 000002, …) contém muitos chunks. O tamanho máximo de cada arquivo é ~512MB para facilitar gerenciamento.
- tombstones: arquivo que registra intervalos de dados deletados manualmente (via API de delete), se houver.
Além dos blocos fechados, existe o Head block (bloco atual em memória) que armazena as métricas em curso. Os dados mais recentes (últimas ~2h) residem em memória para escrita rápida e consultas de curtíssimo prazo.
A cada 2h, o Prometheus “dissolve” parte do Head em um bloco persistente e libera daquela memória. Vamos inspecionar um exemplo de meta.json para entender seus campos:
{
"ulid": "01BKGTZQ1SYQJTR4PB43C8PD98",
"minTime": 1602237600000,
"maxTime": 1602244800000,
"stats": {
"numSamples": 553673232,
"numSeries": 1346066,
"numChunks": 4440437
},
"compaction": {
"level": 1,
"sources": [
"01EM65SHSX4VARXBBHBF0M0FDS",
"01EM6GAJSYWSQQRDY782EA5ZPN"
]
},
"version": 1
}Explicando os campos principais:
- ulid: Identificador único do bloco (um código 128-bit parecido com UUID). Ele é também o nome da pasta do bloco.
- minTime e maxTime: Timestamp inicial e final (epoch em milissegundos) cobertos pelos samples deste bloco. No exemplo, corresponde a um intervalo de 2h.
- stats: Estatísticas do bloco – quantas amostras (numSamples), séries (numSeries) e chunks (numChunks) estão armazenados nele. No exemplo real acima, temos ~1,34 milhão de séries distintas, totalizando 553 milhões de amostras em ~4,44 milhões de chunks dentro desse bloco de 2h. Esses números dão uma noção do volume de dados.
- compaction: Informa o histórico de compactação. level indica quantas vezes já foi compactado (1 significa um bloco resultante da junção de outros menores). sources lista os IDs dos blocos que foram combinados para formar este (no caso, dois blocos anteriores). Se o bloco foi gerado direto do Head (dados “originais”), às vezes sources contém ele próprio.
- version: Versão do formato do bloco/arquivo (para compatibilidade futura).
Com isso, entendemos que cada bloco é imutável depois de escrito. Se novos dados chegam daquele intervalo, seria criado um bloco novo via compaction. Isso facilita a confiabilidade – dados históricos não mudam.
O arquivo de índice (index) serve para mapear as séries e labels aos chunks dentro do bloco. Ele funciona como um índice invertido: dado um nome de métrica e um conjunto de labels, encontra os IDs das séries correspondentes e, então, aponta para os chunks onde estão os dados daquela série.
Assim, ao fazer uma consulta, o Prometheus carrega o índice do bloco relevante e consegue buscar rapidamente somente os chunks necessários (por exemplo, pula chunks inteiros que estão fora do range de tempo consultado, usando informações de minTime/maxtime dos chunks).
O índice é altamente otimizado e comprimido – usa conceitos de posting lists (listas de IDs de séries para cada label-valor) e tabelas de símbolos para strings únicas. Esses detalhes avançados fogem do escopo aqui, mas o importante é: o índice permite que mesmo com milhões de séries por bloco, o Prometheus consiga localizar dados sem varrer tudo linearmente.
Finalmente, o WAL (Write-Ahead Log) é um log de transações recente onde cada amostra coletada é gravada imediatamente no disco antes de ser inserida na memória do Head. Isso garante que, se o Prometheus cair inesperadamente, ao voltar ele pode reprocessar o WAL e recuperar as amostras que ainda não tinham sido compactadas em blocos.
O WAL consiste em arquivos sequenciais (00000000, 00000001, etc.) que vão acumulando as escritas. Periodicamente, o Prometheus faz um checkpoint (snapshot do head) e limpa parte do WAL já aplicado.
Em caso de crash, ele lê desde o último checkpoint para restaurar o estado do Head.
Gerenciamento de memória pelo Prometheus
O Prometheus armazena as séries temporais em memória para rápido acesso às métricas recentes, enquanto grava continuamente os novos dados no disco (WAL) para durabilidade. Isso pode levar a alto uso de RAM e espaço em disco.
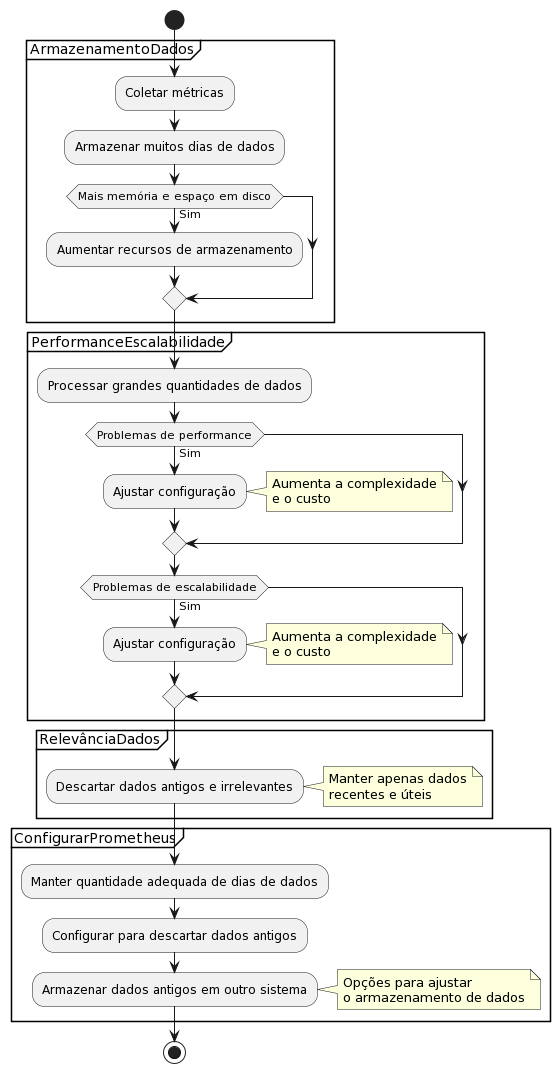
Como mencionado, o Prometheus mantém em RAM todas as séries ativas do bloco atual (tipicamente últimas 2 horas de dados por série). Essa decisão arquitetural visa desempenho: consultas sobre dados recentes (que são as mais comuns, e.g. alertas e dashboards de curto prazo) não precisam esperar leitura de disco – os valores já estão na memória.
Além disso, novas amostras sendo inseridas a cada segundo/minuto são agregadas a estruturas em memória (evitando I/O de disco a cada operação, que seria inviável em alta escala). O resultado é que o consumo de RAM do Prometheus cresce com o número de séries ativas e com a frequência de coleta.
Estima-se, por experiências reportadas, que cada série ativa consome em torno de ~3 KB de RAM (depende de labels, comprimento do nome, etc.). Portanto, 1 milhão de séries pode usar na ordem de 3–4 GB de RAM apenas para manter o head da TSDB.
Em paralelo, o Prometheus escreve todas as amostras no WAL (em disco) para não perdê-las em caso de crash. A cada 2 horas, ele então compacta esses dados quentes em um bloco de 2h comprimido e libera a memória correspondente. Ou seja, há um ciclo onde a memória vai sendo ocupada pelas amostras recentes, e de hora em hora (na verdade 2h) há um flush para disco que esvazia um pouco a memória (mas novas séries podem surgir e ocupar de novo).
O design de manter dados recentes em memória traz a consequência de que o uso de RAM aumenta com a carga de métricas e não é liberado até que os blocos sejam fechados ou as séries cessem. Em períodos de pico (muitas séries novas aparecendo rapidamente), o Prometheus pode chegar a consumir muita memória para acompanhar.
Se faltar RAM, o processo corre risco de OOM (matar por falta de memória) ou, no melhor caso, o sistema operacional vai começar a usar swap – o que degrada muito a performance. Na imagem acima, vemos que tanto a RAM quanto o armazenamento em disco podem crescer substancialmente à medida que aumentamos o volume de dados monitorados.
Quanto mais dias de retenção mantidos no Prometheus, mais recursos são usados e maior o esforço para consultas longas. Manter dados históricos demais pode sobrecarregar a memória e o disco, além de dificultar encontrar informações recentes relevantes.
Embora possamos configurar retenções longas (30, 60 dias), isso não significa que o Prometheus foi otimizado para operar eficientemente com esse histórico todo localmente. Lembre-se: ele não indexa por data de forma distribuída – consultas que abrangem muitos dias terão que ler vários blocos do disco e processar um grande volume de amostras.
Na prática, reter além de algumas semanas começa a tornar as consultas bem lentas e o uso de disco muito alto (sem falar nos backups dessa quantidade de data). Consultas extensas acabam exigindo leitura de múltiplos blocos e processamento de grandes volumes de dados, o que impacta diretamente a performance do sistema.
A imagem acima ilustra que, à medida que guardamos mais dias, o custo de recursos cresce e pode inclusive ofuscar tendências atuais no meio de tanto dado antigo.
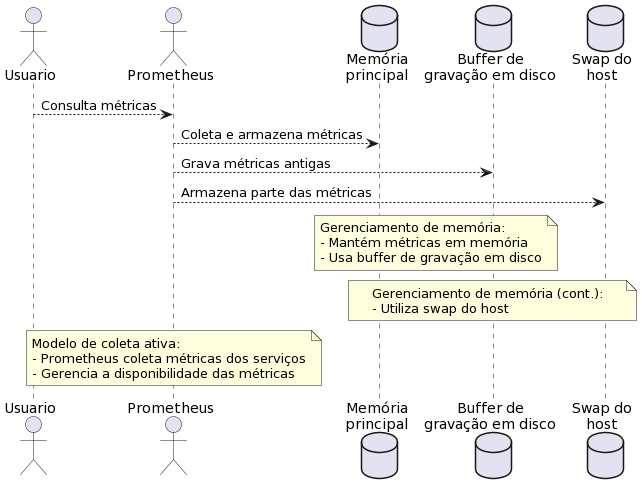
A filosofia do Prometheus é ser a ferramenta de monitoramento em tempo real e de curto/médio prazo.
Para análises históricas longas ou compliance (guardar métricas por 1 ano, por exemplo), a solução comum é integrar um back-end de longo prazo (Thanos, Cortex, databases remotas) que arquivem esses dados, enquanto o Prometheus local mantém só o necessário para operação/alertas recentes.
Assim você tem o melhor dos dois mundos: rapidez no real-time e histórico completo disponível quando precisar, sem sobrecarregar o Prometheus diariamente.
Todas as amostras recentes residem na memória principal (Head), com flush periódico para disco a cada 2 horas. O WAL no disco captura as escritas para garantir durabilidade. Em situação de carga extrema, o OS pode usar swap, mas isso deve ser evitado pois degrada o desempenho.
Vamos recapitular o ciclo de vida dos dados no Prometheus e seu impacto em memória/disco:
-
Head Block (memória): Novas séries e amostras entram aqui. As séries ativas ocupam estruturas na heap da aplicação Go do Prometheus. A cada amostra recebida, ela também é anexada no WAL (no SSD/disco) para registro permanente. Durante até ~2h, os dados ficam disponíveis no Head para consultas instantâneas. Por isso, consultas e alertas em dados “frescos” são muito rápidas.
-
Flush para bloco persistente: Quando o intervalo de 2h se completa, o Prometheus corta o bloco (na verdade ele espera 2h ou 1h30 dependendo de certas condições) e escreve um novo bloco no diretório data (contendo aqueles 2h de amostras agora imutáveis, já comprimidas). Em seguida, libera da memória boa parte das estruturas referentes àquele intervalo. O head então mantém somente as séries ainda ativas que extrapolem o próximo bloco.
-
Compaction: Após algumas rotações de bloco, o Prometheus agrupa blocos menores em blocos maiores (por exemplo, une 5 blocos de 2h em 1 bloco de 10h, e assim por diante). Isso ocorre em segundo plano e ajuda a reduzir o número de arquivos e melhorar compressão geral. Compaction consome CPU/disk I/O, mas é intercalado para não interferir muito.
-
Retenção e cleanup: Quando um bloco excede a retenção configurada (ex: ficou mais velho que 15 dias), ele é marcado para deleção. A limpeza ocorre periodicamente e remove blocos expirados. Importante: a remoção não é imediata ao passar do prazo – o processo de cleanup roda em intervalos (até 2h de delay). Durante a limpeza, o Prometheus deleta os diretórios daqueles blocos antigos, liberando espaço em disco.
-
Reinício e recuperação: Se o Prometheus reiniciar ou cair, na inicialização ele precisa recarregar o estado. Ele vai abrir todos os blocos persistentes (apenas meta e índice, sem carregar todos os dados) e principalmente processar o WAL para recriar o Head com as amostras que ainda não estavam em bloco. Esse processo de recuperação do WAL pode demorar dependendo do tamanho (por isso há checkpoint para otimizar). Ao final, o sistema retorna ao estado como se nunca tivesse parado (exceto pelos minutos offline onde dados podem ter se perdido se os alvos não suportam retroativa).
Tudo isso explica por que o Prometheus consome bastante memória: ele aposta em manter as séries recentes acessíveis e indexadas para respostas rápidas.
Num Prometheus com muitos alvos ou alta cardinalidade (muitas combinações de labels), o consumo de RAM pode facilmente ser o principal limitador. Conforme mencionado anteriormente, 1 milhão de séries ativas pode exigir vários GB de RAM, portanto planeje a capacidade de acordo com o volume de métricas esperado.
Infelizmente, não há muito tunings manuais a fazer na memória além de reduzir a quantidade de dados: menos séries ou menor frequência de coleta = menos uso de RAM. O Prometheus não tem um mecanismo interno de shard automático ou flush mais frequente (o flush é fixo ~2h por design).
Então, as soluções se resumem a escalar verticalmente (máquinas com mais memória, CPU, disco rápido) ou escalar horizontalmente (dividir a carga entre vários Prometheus, cada um monitorando uma parte das targets). Nas melhores práticas a seguir, daremos dicas para mitigar esses desafios de desempenho e dimensionamento.
Native Histograms (Recurso Experimental)
O Prometheus introduziu Native Histograms como um recurso experimental nas versões mais recentes (2.40+). Essa funcionalidade representa uma evolução significativa na forma como histogramas são armazenados e consultados.
Diferenças dos Histogramas Tradicionais
Histogramas tradicionais:
- Usam buckets predefinidos (ex: 0.1, 0.5, 1.0, 2.5, 5.0, 10.0)
- Cada bucket gera uma série separada (
_bucket) - Requerem múltiplas séries para representar uma distribuição
- Limitados pela granularidade dos buckets
Native Histograms:
- Usam buckets dinâmicos e adaptativos
- Armazenam a distribuição completa em uma única série
- Permitem maior precisão nos percentis
- Reduzem significativamente o número de séries
Configuração
Para habilitar native histograms, adicione a flag experimental:
prometheus --enable-feature=native-histogramsOu no Docker:
command:
- '--enable-feature=native-histograms'Exemplo de Uso
Instrumentação com native histograms (Go):
import (
"github.com/prometheus/client_golang/prometheus"
"github.com/prometheus/client_golang/prometheus/promauto"
)
var (
requestDuration = promauto.NewHistogram(prometheus.HistogramOpts{
Name: "http_request_duration_seconds",
Help: "Duration of HTTP requests",
NativeHistogramBucketFactor: 1.1, // Fator de crescimento dos buckets
NativeHistogramMaxBucketNumber: 100, // Máximo de buckets
})
)Consulta de percentis:
# Percentil 95 usando native histogram
histogram_quantile(0.95, rate(http_request_duration_seconds[5m]))
# Percentil 99
histogram_quantile(0.99, rate(http_request_duration_seconds[5m]))Vantagens
- Menos séries: Uma métrica de latência que antes gerava 10+ séries agora gera apenas 1
- Maior precisão: Buckets adaptativos capturam melhor a distribuição real
- Melhor performance: Menos overhead de armazenamento e consulta
- Compatibilidade: Funciona com todas as funções PromQL existentes
Considerações
- Experimental: Ainda em desenvolvimento, pode ter mudanças na API
- Migração: Requer atualização das bibliotecas cliente
- Compatibilidade: Funciona apenas com versões recentes do Prometheus
Nota: Native histograms são especialmente úteis para métricas de latência em aplicações de alta performance, onde a precisão dos percentis é crítica.
Melhores Práticas
Depois de entender a mecânica interna do Prometheus, é válido reunir algumas recomendações para tirar o melhor proveito da ferramenta de forma escalável e confiável.
Planejamento de Capacidade
-
Estime volume de métricas e retenção: Antes de implantar, faça uma estimativa do número de séries que você vai coletar e defina uma retenção condizente. Lembre que por padrão são 15 dias. Se não precisar de tudo isso para monitoramento diário, retenções menores aliviam recursos. Ao contrário, se precisar de mais tempo histórico, esteja ciente do aumento de disco e possivelmente avalie armazenamento remoto.
-
Monitore o Prometheus em si: “Quis custodiet ipsos custodes?” – o Prometheus expõe suas próprias métricas (no endpoint /metrics dele). Use um outro Prometheus ou a mesma instância para monitorar métricas como
prometheus_tsdb_head_series(número de séries no head),prometheus_tsdb_head_samples_appended_total(samples inseridos por segundo),prometheus_engine_query_duration_seconds(latência das consultas), etc. Isso alerta para crescimento de cardinalidade inesperado ou consultas muito pesadas rodando. -
Dimensione hardware adequadamente: Regra empírica: 1 CPU core pode processar aproximadamente até 200k amostras por segundo (varia, mas é uma ideia). Memória, calcule ~3kB por série ativa. Disco: ~1-2 bytes por amostra armazenada comprimida (15 dias, 200 milhões de amostras ~ 200-300MB). Use SSDs rápidos – operações de WAL e blocos beneficiam de I/O rápido.
Organização de Métricas e Labels
-
Consistência na nomeação: Siga convenções de nomenclatura para facilitar a vida. Use nomes descritivos e padronizados (letras minúsculas, separadas por underscores, unidade no sufixo se aplicável:
_seconds,_bytes,_totalpara contadores acumulativos). Por exemplo, prefiraapp_memory_usage_bytesa algo comoMemUsedou outras variações inconsistentes. Isso ajuda todo mundo a entender do que se trata sem ambiguidade. -
Labels estratégicos: Anexe labels que façam sentido de consulta, mas evite rotular com informações que tenham alta cardinalidade ou unicidade. Um bom label é algo como
region,datacenter,instance(desde que este não seja único por métrica – use instance só onde faz sentido). Maus labels incluem: ID de requisição, nome de usuário, URL completa (em vez de caminho genérico), timestamp, IP dinâmico de cliente. Esses valores criam um número enorme de séries distintas. Lembre-se: cada combinação diferente de labels vira uma série separada no TSDB. Se você tiver 1000 usuários e rotular métricas por usuário, virou 1000 séries onde antes podia ser 1 ou algumas. Leve isso em conta. -
Explosão de cardinalidade: É um dos problemas mais comuns. Por exemplo, adicionar um label
product_ida uma métrica de pedidos, onde product_id pode assumir dezenas de milhares de valores, multiplicará as séries. Isso pode levar o Prometheus a consumir toda memória e travar. Portanto, só use labels cujo conjunto de valores possível seja limitado e relativamente pequeno. (Regra de bolso: algumas dezenas ou poucas centenas de valores diferentes por label no máximo. Mais que isso, pense duas vezes se é necessário.) Caso precise monitorar algo muito cardinal (ex: métricas por usuário único), talvez o Prometheus não seja a ferramenta adequada ou você precisa agregá-las antes de expor.
O Inimigo nº 1: Explosão de Cardinalidade
A cardinalidade é o maior desafio do Prometheus. Cada combinação única de labels cria uma série temporal separada no TSDB. Quando você adiciona labels com valores altamente variáveis (como IDs de usuário, timestamps, URLs completas, ou IPs dinâmicos), você está multiplicando exponencialmente o número de séries armazenadas.
Por que é tão perigoso:
- Consumo de memória: Cada série ativa consome ~3kB de RAM. Milhares de séries = gigabytes de memória
- Performance de consultas: Mais séries = consultas mais lentas e maior uso de CPU
- Instabilidade: Cardinalidade excessiva pode fazer o Prometheus travar ou reiniciar constantemente
- Custos de armazenamento: Mais séries = mais dados para armazenar e processar
Exemplos de labels perigosos:
user_id(pode ter milhões de valores únicos)request_id(único por requisição)timestamp(muda a cada scrape)ip_address(muito variável)full_url(em vez de usarendpointoupath)
Soluções práticas:
- Agregação prévia: Agregue métricas antes de expô-las ao Prometheus
- Labels limitados: Use apenas labels com valores limitados e previsíveis
- Métricas de resumo: Em vez de métricas por item individual, use métricas de contagem/total
- Filtros inteligentes: Use relabeling para remover labels problemáticos
- Monitoramento ativo: Monitore
prometheus_tsdb_head_seriespara detectar crescimento anormal
Regra de ouro: Se você não consegue prever quantos valores diferentes um label pode ter, provavelmente não deveria usá-lo no Prometheus.
- Métricas altas vs baixas cardinalidades: Prefira métricas mais agregadas. Por exemplo, em vez de registrar uma métrica separada para cada item em fila (que não faz sentido), registre o tamanho da fila como um gauge. Em vez de métricas por sessão de usuário, exponha total global ou por categoria de usuário. Enfim, modele os dados de forma a minimizar detalhes desnecessários.
Consultas (PromQL) Eficientes
-
Cuidado com funções custosas: Algumas funções PromQL podem ser muito úteis, porém custosas.
topk()ebottomk(), por exemplo, obrigam o engine a ordenar muitas séries para achar o top N – pode ser caro se aplicado numa métrica com milhares de séries. Use-as com moderação (talvez em queries de background para dashboard, mas evite em alertas críticos se possível). Similar para agregações sem restrição:sum by (label)onde label tem muitos valores, o Prometheus terá que materializar todas combinações. -
Use intervalos de tempo adequados: Querys do tipo [5m], [1h] etc. definem quanto tempo de dados vão considerar. Evite pedir mais do que precisa. Por exemplo, se um alerta precisa saber a taxa nos últimos 5 minutos, não use 1h. Intervalos maiores = mais dados lidos e processados. Num gráfico, também não exagere no zoom out se não for necessário – muitos dados tornam a renderização e transmissão pesadas.
-
Prefira
rate()ouincrease()para contadores ao invés deirate()para alertas contínuos: A funçãoirate()calcula instantaneamente a derivada entre os dois últimos pontos – isso é útil às vezes, mas tende a ser muito “barulhento” (variação instante a instante). Em dashboards e alertas gerais,rate()numa janela de pelo menos 1m ou 5m é mais estável e representativo da taxa média. Useiratesomente quando quer realmente capturar spikes momentâneos e tem alta frequência de scrape. -
Agregue no scraping quando possível: Se você já sabe que nunca vai olhar cada instância individual de certa métrica, poderia agregá-la antes mesmo de enviar. Exemplo: se você tem 10 threads fazendo trabalho idêntico e só quer saber o total combinado, exponha uma única métrica total e não 10 separadas. Claro que isso depende do caso de uso – muitas vezes queremos o detalhe – mas é algo a pensar.
-
Limite consultas no UI: O Prometheus permite rodar qualquer PromQL ad-hoc no UI ou via API. Em ambientes compartilhados, controle o acesso ou conscientize os usuários para não rodarem consultas insanas (tipo um sum sem nenhum label em milhões de séries por 365d) que possam afetar a performance. Você pode habilitar autenticação/TLS e até colocar um proxy com quotas se for necessário proteger a API de uso indevido.
Arquitetura e Escalabilidade
-
Sharding (divisão de carga): Se chegar ao ponto de um único Prometheus não dar conta (seja por limite de CPU/RAM ou por questões organizacionais), considere dividir os alvos entre múltiplas instâncias. Por exemplo, rodar um Prometheus por cluster Kubernetes, ou por ambiente (dev/prod), ou por região geográfica. Cada um monitora só seu âmbito. Você pode replicar as regras de alertas em todos (assim cada local alerta independentemente). Para métricas globais, use federação ou uma camada agregadora (como Thanos) para unificar se necessário.
-
Alta disponibilidade: O Prometheus em si não é HA – ele é stand-alone. Se cair, fica um buraco de coleta enquanto estiver fora. Uma prática comum em produção é rodar dois Prometheus em paralelo coletando os mesmos alvos (nas mesmas configurações) – assim, se um falhar, o outro continua e nenhuma métrica se perde. O Alertmanager pode receber alertas duplicados de ambos, mas ele deduplica automaticamente (precisa configurar ambos Prometheus com o mesmo external_label cluster). Essa abordagem gasta mais recursos (coleta em dobro), mas é simples e efetiva para HA de alertas.
-
Longo prazo e agregação global: Conforme citado, se precisar escalar horizontalmente de verdade ou guardar métricas por longos períodos, vale integrar soluções como Thanos, Cortex ou Grafana Mimir. Essas ferramentas armazenam dados em base de dados distribuída (por exemplo, S3 ou BigTable no caso do Thanos/Cortex) e permitem rodar consultas PromQL que abrangem múltiplos Prometheus “como se fosse um só”.
O Thanos, por exemplo, atua como um sidecar pegando os dados de cada Prometheus e enviando para o objeto storage, depois uma camada de querier unifica as consultas. O Grafana Mimir segue arquitetura semelhante, nascida da experiência do Cortex, permitindo escala praticamente ilimitada (bilhões de séries) e alta disponibilidade, com compatibilidade total com PromQL e remote write. Claro, adicionam complexidade – mas são soluções maduras mantidas pela CNCF/Grafana Labs.
- Federação bem aplicada: Caso use federação, siga a orientação de federar apenas métricas já agregadas e necessárias globalmente. Por exemplo, federar só métricas começando com
job:(indicando que são resultados de recording rules já agregadas). Não federar todas as métricas crus. E realize alertas localmente, deixando o global só para visualização.
Segurança
-
Não exponha sem proteção em redes inseguras: O Prometheus, por padrão, não tem autenticação nem TLS habilitados. Se você for disponibilizar a interface ou API em rede pública ou multi-tenant, coloque-o atrás de um proxy reverso que implemente TLS e autenticação (básica, OAuth, o que for). Alternativamente, rode em rede interna/VPN somente. Há flags experimentais para TLS direto e auth no Prometheus, mas a abordagem recomendada ainda é usar um proxy (por exemplo, Nginx, Traefik, etc).
-
Controle acesso à API: Considere habilitar autorização se for um ambiente com vários usuários ou multi-time. Infelizmente, o Prometheus não suporta múltiplos níveis de usuário nativamente. A solução costuma ser segregar instâncias ou novamente um proxy que filtre rotas. Por exemplo, impedir acesso direto ao
/api/v1/admin(que possui comandos de deleção de dados). -
Atualizações e patches: Mantenha o Prometheus atualizado – a cada versão há otimizações e correções, inclusive de segurança. E.g., compressão de WAL veio ativada por padrão na 2.20, reduzindo disco pela metade. Versões mais novas introduziram native histograms (experimental) e melhorias de desempenho. Então acompanhe o changelog oficial e planeje upgrade regularmente (Prometheus é bem compatível retroativamente em dados e configs, upgrades diretos costumam ser tranquilos).
-
Isolamento de rede para exporters: Exporters muitas vezes expõem métricas sensíveis (por exemplo, o Node Exporter expõe informações de hardware, usuários logados etc.). É boa prática deixar esses endpoints acessíveis só pelo Prometheus, não abertos ao mundo. Use firewalls/regras de segurança nos hosts ou config de container network para limitar.
-
Naming anti-collision: Se você usa rótulos externos (external_labels) para identificar instâncias em um contexto federado ou HA, garanta que cada Prometheus tenha um label único (e.g.,
cluster="eu-west-1"). Isso evita confusão de métricas vindas de origens diferentes no caso de junção (Thanos, federação) e ajuda a filtrar.
Backup, Recovery e Upgrade
Em ambientes de produção, é fundamental ter estratégias robustas para backup, recuperação de falhas e upgrades do Prometheus. Esses aspectos são frequentemente negligenciados, mas são críticos para manter a continuidade do monitoramento.
Backup de Dados
O Prometheus armazena dados no diretório data/ que contém os blocos de séries temporais. Para fazer backup consistente:
Backup a quente (recomendado):
# Parar o Prometheus para garantir consistência
sudo systemctl stop prometheus
# Fazer backup do diretório data
tar -czf prometheus-backup-$(date +%Y%m%d).tar.gz /opt/prometheus/data/
# Reiniciar o Prometheus
sudo systemctl start prometheusBackup a frio (alternativa):
# Usar promtool para verificar integridade antes do backup
promtool tsdb check /opt/prometheus/data/
# Fazer backup apenas dos blocos fechados (mais seguro)
find /opt/prometheus/data/ -name "*.json" -exec tar -czf prometheus-blocks-$(date +%Y%m%d).tar.gz {} \;Backup de configuração:
# Backup dos arquivos de configuração
cp /etc/prometheus/prometheus.yml /backup/prometheus.yml.$(date +%Y%m%d)
cp /etc/prometheus/alert.rules.yml /backup/alert.rules.yml.$(date +%Y%m%d)Recuperação de Falhas
Restauração de dados:
# Parar o Prometheus
sudo systemctl stop prometheus
# Restaurar backup
tar -xzf prometheus-backup-20231201.tar.gz -C /
# Verificar integridade dos dados
promtool tsdb check /opt/prometheus/data/
# Reiniciar
sudo systemctl start prometheusRecuperação de WAL corrompido:
# Se o WAL estiver corrompido, pode ser necessário recriar
rm -rf /opt/prometheus/data/wal/
rm -rf /opt/prometheus/data/chunks_head/
# Reiniciar - o Prometheus recriará o WAL
sudo systemctl start prometheusEstratégias de Upgrade
Upgrade direto (mais comum):
# Fazer backup antes do upgrade
sudo systemctl stop prometheus
tar -czf prometheus-backup-pre-upgrade.tar.gz /opt/prometheus/data/
# Baixar nova versão
wget https://github.com/prometheus/prometheus/releases/download/v2.45.0/prometheus-2.45.0.linux-amd64.tar.gz
tar -xzf prometheus-2.45.0.linux-amd64.tar.gz
# Substituir binário
cp prometheus-2.45.0.linux-amd64/prometheus /opt/prometheus/
cp prometheus-2.45.0.linux-amd64/promtool /opt/prometheus/
# Verificar configuração
/opt/prometheus/promtool check config /etc/prometheus/prometheus.yml
# Reiniciar
sudo systemctl start prometheusUpgrade com rollback:
# Manter versão anterior
cp /opt/prometheus/prometheus /opt/prometheus/prometheus.backup
# Fazer upgrade
# ... (mesmo processo acima)
# Se houver problemas, rollback
sudo systemctl stop prometheus
cp /opt/prometheus/prometheus.backup /opt/prometheus/prometheus
sudo systemctl start prometheusConsiderações Importantes
Compatibilidade de dados:
- O Prometheus mantém compatibilidade retroativa de dados entre versões menores
- Upgrades major (ex: 2.x para 3.x) podem requerer migração de dados
- Sempre verifique o changelog oficial antes de upgrades
Tempo de recuperação:
- O Prometheus pode demorar para processar o WAL após reinicialização
- Em ambientes com muitas séries, a recuperação pode levar minutos
- Monitore
prometheus_tsdb_wal_replay_duration_secondsdurante recuperação
Backup automatizado:
#!/bin/bash
# Script de backup automatizado
DATE=$(date +%Y%m%d_%H%M%S)
BACKUP_DIR="/backup/prometheus"
# Criar backup
sudo systemctl stop prometheus
tar -czf $BACKUP_DIR/prometheus-$DATE.tar.gz /opt/prometheus/data/
sudo systemctl start prometheus
# Manter apenas últimos 7 backups
find $BACKUP_DIR -name "prometheus-*.tar.gz" -mtime +7 -deleteMonitoramento de integridade:
# Alertas para problemas de backup/recuperação
groups:
- name: prometheus_backup
rules:
- alert: PrometheusBackupFailed
expr: time() - prometheus_build_info > 86400 # Mais de 1 dia sem restart
for: 1h
labels:
severity: warning
annotations:
summary: "Prometheus não foi reiniciado recentemente (possível problema de backup)"Importante: Sempre teste backups e procedimentos de recuperação em ambiente de desenvolvimento antes de aplicar em produção. A integridade dos dados de monitoramento é tão crítica quanto os dados da aplicação.
Seguindo essas práticas, você deverá manter seu ambiente Prometheus funcionando de forma mais suave, evitando as armadilhas comuns de desempenho e garantindo que as métricas coletadas realmente agreguem valor (e alertas disparem quando devem, sem falso positivos ou negativos).
Operação e Manutenção
Promtool
O promtool é uma ferramenta de linha de comando que acompanha o Prometheus, fornecendo utilitários para verificar configurações e depurar dados. Algumas utilizações comuns do promtool:
- Checar sintaxe de configuração: Antes de subir uma alteração no
prometheus.yml, rodepromtool check config prometheus.yml. Ele apontará erros de sintaxe ou campos desconhecidos, ajudando a evitar falhas no start do servidor. - Validar regras de alerta ou gravação: Se você definiu arquivos externos de regras (YAML de alertas ou recording rules), use
promtool check rules minhas_regras.yml. Ele analisará as expressões PromQL e a formatação. - Testar expressão de alerta: O promtool permite avaliar manualmente expressões em um dado instantâneo ou série de tempo para ver se disparariam alerta. Útil em CI ou para garantir que a lógica está correta.
- Checar integridade do TSDB: Com o comando
promtool tsdb check /path/para/dadosé possível inspecionar o banco local de séries temporais em busca de inconsistências ou corrupção. - Converter formatos de dados de métrica: Há como transformar arquivos de métricas entre formatos (por exemplo, de texto para JSON e vice-versa) usando
promtool convert metrics --from=txt --to=json arquivo.txt.
Essas são apenas algumas funções. Em suma, o promtool é seu amigo para garantir que o ambiente Prometheus está consistente e saudável – use-o sempre que fizer mudanças significativas na configuração.
Conclusão
Neste artigo, exploramos em detalhes o Prometheus – desde conceitos fundamentais até seu funcionamento interno e implicações práticas de operação. Vimos como ele implementa um banco de dados de séries temporais altamente eficiente, mantendo dados recentes em memória para rapidez e usando compressão e segmentação em blocos para histórico em disco.
Também analisamos aspectos como modelo de coleta pull, linguagem de consulta poderosa, uso intensivo de recursos proporcionais ao volume de métricas, e formas de contornar limitações (sejam arquiteturais ou de escala) com boas práticas e ferramentas auxiliares.
Esses pontos mostram como o Prometheus alia eficiência técnica a flexibilidade operacional, permitindo que equipes monitorem ambientes complexos e em constante evolução, ao mesmo tempo em que enfrentam desafios de escala e desempenho com soluções práticas e acessíveis.
O Prometheus se destaca no ecossistema de monitoramento por sua simplicidade de implantação e por ter sido projetado desde o início para ambientes de microsserviços e infraestrutura dinâmica. Seu modelo multidimensional de métricas com labels e o PromQL possibilitam análises ricas e alertas robustos com relativamente pouco esforço de configuração.
É notável como em poucos anos ele se tornou um dos pilares da observabilidade moderna, ao lado de ferramentas complementares para logs (ELK stack) e tracing (Jaeger, etc.).
Por outro lado, entendemos que o Prometheus não resolve tudo sozinho: retenção de longo prazo, alta disponibilidade nativa e escalabilidade horizontal são pontos fora do escopo do core do Prometheus.
Em vez de tentar ser distribuído, o projeto optou por interfaces (remote write/read) e pela filosofia de componibilidade – cabendo a outras peças (como Thanos ou Mimir) suprir essas demandas quando necessárias.
Essa decisão de design mantém o Prometheus “enxuto” e confiável, mas significa que para crescer além de certo limite, precisamos arquitetar bem a solução de monitoramento abrangendo outros componentes.
Recapitulando alguns aprendizados chave:
- Organize bem suas métricas e labels para evitar sobrecarga de cardinalidade.
- Monitore o próprio Prometheus e ajuste a capacidade conforme crescimento.
- Use Alertmanager e outras integrações para ter um uso completo (coleta, armazenamento, alerta, visualização).
- Em caso de grandes escalas, parta para sharding ou ferramentas de escala distribuída – não force um Prometheus único a fazer trabalho demais.
- Leve em conta segurança e isolamento, pois monitoramento também lida com informações sensíveis do ambiente.
Esperamos que este guia tenha fornecido insights valiosos, tanto para iniciantes entenderem os conceitos do Prometheus quanto para usuários experientes refinarem sua utilização. Compreender o “under the hood” do Prometheus ajuda a antecipar comportamentos, otimizar configurações e evitar armadilhas comuns na operação diária.
O Prometheus continua em rápida evolução (com melhorias na TSDB, novos recursos como Exemplos Exemplares e Native Histograms em teste, etc.), e o ecossistema ao seu redor também. Fique atento a atualizações e boas práticas emergentes – a comunidade CNCF e blogs como o Robust Perception regularmente publicam conteúdos de alto nível a respeito.
No mais, boas métricas e bons alertas!
Referências
- Documentação Oficial do Prometheus – especialmente a Overview , Metric Types , Best Practices e seção de Storage .
- Blog Robust Perception (Brian Brazil) – várias postagens aprofundadas, por exemplo: “Federation, what is it good for?” , “How much RAM does Prometheus 2.x need…” , “Using JSON file service discovery” .
- Ganesh Vernekar – Série de artigos “Prometheus TSDB” – Parts 1-7 no blog do Ganesh (engenheiro Grafana Labs) detalhando a fundo a arquitetura do TSDB. Em especial, Parte 4: Blocos persistentes e Índice .
- Livro “Prometheus Up & Running” (O’Reilly, 2019) – de Brian Brazil, ótima introdução abrangendo do básico a casos avançados.
- Livro “The Prometheus Book” de James Turnbull – guia prático cobrindo instalação, instrumentação e alertas (disponível online).
- Hands-On Infrastructure Monitoring with Prometheus (Packt) – livro focado em exemplos práticos de uso do Prometheus em cenários reais.
- Monitoring Microservices and Containerized Applications (Apress) – aborda Prometheus em contexto de microsserviços/Kubernetes.
- Comparativos Prometheus vs. outras ferramentas: Artigos como “Prometheus vs. ELK”, “Prometheus vs. Grafana Mimir (Cortex)”, e posts do blog da BetterStack sobre melhores práticas.
- Grafana Mimir – Página oficial e anúncio do lançamento em 2022, mostrando como escalar Prometheus para 1 bilhão de séries.
- Datadog e New Relic – documentações e sites oficiais para entender ofertas de monitoramento proprietárias integradas (APM, Logs, etc.), útil para ver diferenças de escopo.
- Nagios/Core e Zabbix – documentação e comunidade, para contexto histórico de monitoramento (foco em disponibilidade, sem TSDB nativo).
- ELK Stack – docs Elastic e blogs de terceiros comparando com Prometheus (focando que ELK é logs e Prometheus métricas).
- CNCF Observability Landscape – projetos e ferramentas relacionadas, para quem quiser explorar além (OpenTelemetry, Fluentd, etc.).
💬 Comentários